For our latest survey data about news influencers, read the “News Influencers Fact Sheet.”
This report – a study of popular news influencers – uses three different research components and methodologies, including a nationally representative survey of U.S. adults conducted through Pew Research Center’s American Trends Panel (ATP), as well as an analysis of news influencers and posts from those accounts from three distinct time periods in 2024.
This is the latest report from the Pew-Knight Initiative, a research program funded jointly by The Pew Charitable Trusts and the John S. and James L. Knight Foundation. Find related reports online at https://www.pewresearch.org/pew-knight/.
Survey
The American Trends Panel survey methodology
Overview
Data in this report comes from Wave 150 of the American Trends Panel (ATP), Pew Research Center’s nationally representative panel of randomly selected U.S. adults. The survey was conducted from July 15 to Aug. 4, 2024. A total of 10,658 panelists responded out of 12,188 who were sampled, for a survey-level response rate of 87%.
The cumulative response rate accounting for nonresponse to the recruitment surveys and attrition is 3%. The break-off rate among panelists who logged on to the survey and completed at least one item is less than 1%. The margin of sampling error for the full sample of 10,658 respondents is plus or minus 1.2 percentage points.
SSRS conducted the survey for Pew Research Center via online (n=10,262) and live telephone (n=396) interviewing. Interviews were conducted in both English and Spanish.
To learn more about the ATP, read “About the American Trends Panel.”
Panel recruitment
Since 2018, the ATP has used address-based sampling (ABS) for recruitment. A study cover letter and a pre-incentive are mailed to a stratified, random sample of households selected from the U.S. Postal Service’s Computerized Delivery Sequence File. This Postal Service file has been estimated to cover 90% to 98% of the population.3 Within each sampled household, the adult with the next birthday is selected to participate. Other details of the ABS recruitment protocol have changed over time but are available upon request.4 Prior to 2018, the ATP was recruited using landline and cellphone random-digit-dial surveys administered in English and Spanish.
A national sample of U.S. adults has been recruited to the ATP approximately once per year since 2014. In some years, the recruitment has included additional efforts (known as an “oversample”) to improve the accuracy of data for underrepresented groups. For example, Hispanic adults, Black adults and Asian adults were oversampled in 2019, 2022 and 2023, respectively.
Sample design
The overall target population for this survey was noninstitutionalized persons ages 18 and older living in the United States. All active panel members were invited to participate in this wave.
Questionnaire development and testing
The questionnaire was developed by Pew Research Center in consultation with SSRS. The web program used for online respondents was rigorously tested on both PC and mobile devices by the SSRS project team and Pew Research Center researchers. The SSRS project team also populated test data that was analyzed in SPSS to ensure the logic and randomizations were working as intended before launching the survey.
Incentives
All respondents were offered a post-paid incentive for their participation. Respondents could choose to receive the post-paid incentive in the form of a check or gift code to Amazon.com. Incentive amounts ranged from $5 to $20 depending on whether the respondent belongs to a part of the population that is harder or easier to reach. Differential incentive amounts were designed to increase panel survey participation among groups that traditionally have low survey response propensities.
Data collection protocol
The data collection field period for this survey was July 15 to Aug. 4, 2024. Surveys were conducted via self-administered web survey or by live telephone interviewing.
For panelists who take surveys online:5 Postcard notifications were mailed to a subset on July 15.6 Survey invitations were sent out in two separate launches: soft launch and full launch. Sixty panelists were included in the soft launch, which began with an initial invitation sent on July 15. All remaining English- and Spanish-speaking sampled online panelists were included in the full launch and were sent an invitation on July 16.
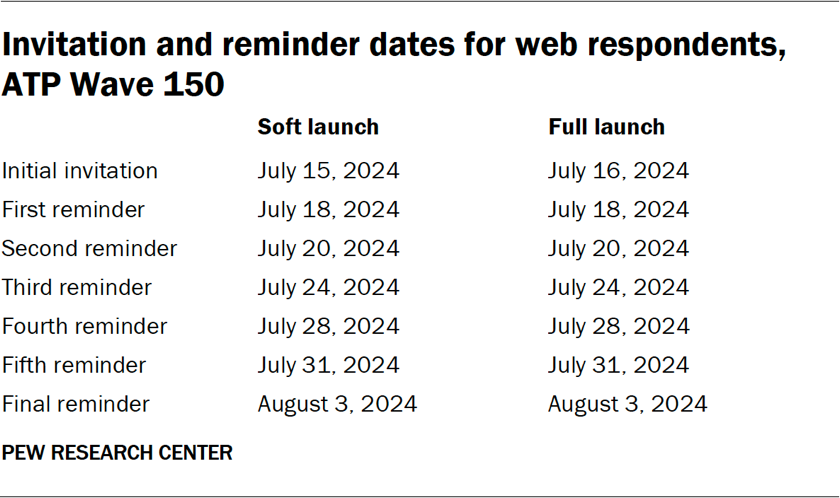
Panelists participating online were sent an email invitation and up to six email reminders if they did not respond to the survey. ATP panelists who consented to SMS messages were sent an SMS invitation with a link to the survey and up to six SMS reminders.
For panelists who take surveys over the phone with a live interviewer: Prenotification postcards were mailed on July 10, and reminder postcards were mailed on July 15. Ten CATI panelists were included in the soft launch, for which dialing began on July 15. CATI panelists receive up to six calls from trained SSRS interviewers.
Data quality checks
To ensure high-quality data, Center researchers performed data quality checks to identify any respondents showing patterns of satisficing. This includes checking for whether respondents left questions blank at very high rates or always selected the first or last answer presented. As a result of this checking, five ATP respondents were removed from the survey dataset prior to weighting and analysis.
Weighting
The ATP data is weighted in a process that accounts for multiple stages of sampling and nonresponse that occur at different points in the panel survey process. First, each panelist begins with a base weight that reflects their probability of recruitment into the panel. These weights are then calibrated to align with the population benchmarks in the accompanying table to correct for nonresponse to recruitment surveys and panel attrition. If only a subsample of panelists was invited to participate in the wave, this weight is adjusted to account for any differential probabilities of selection.
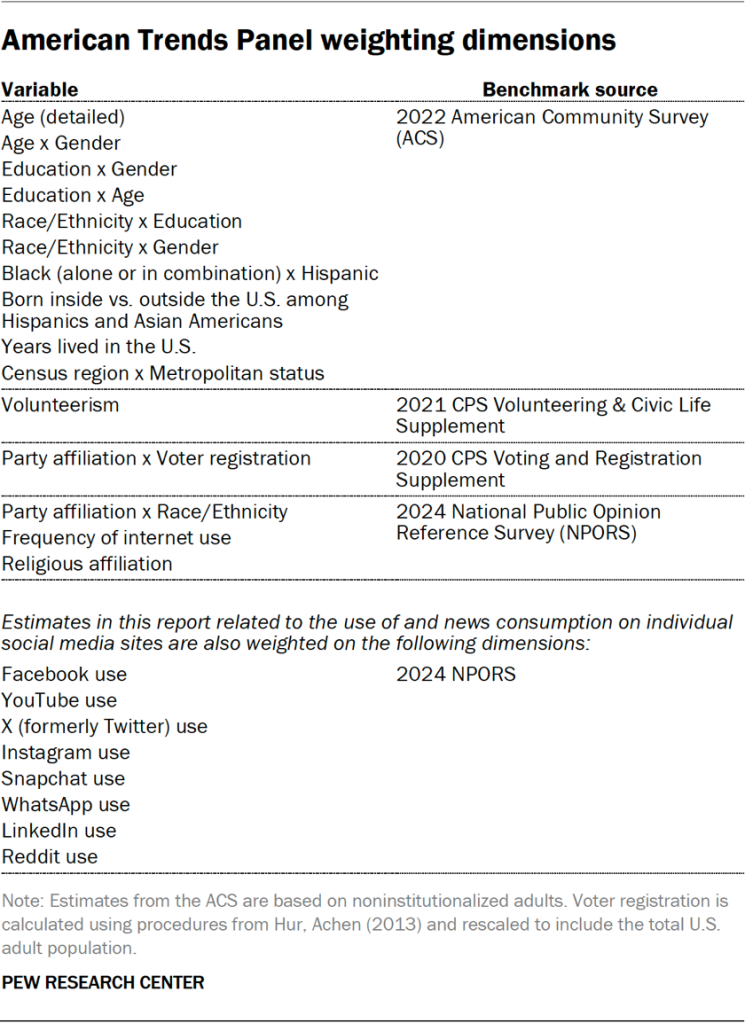
Among the panelists who completed the survey, this weight is then calibrated again to align with the population benchmarks identified in the accompanying table. The weight is then trimmed at the 1st and 99th percentiles to reduce the loss in precision stemming from variance in the weights. Sampling errors and tests of statistical significance take into account the effect of weighting.
The following table shows the unweighted sample size and the error attributable to sampling that would be expected at the 95% level of confidence for the full sample in the survey.

Sample sizes and sampling errors for other subgroups are available upon request. In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Dispositions and response rates


How family income tiers are calculated
Family income data reported in this study is adjusted for household size and cost-of-living differences by geography. Panelists then are assigned to income tiers that are based on the median adjusted family income of all American Trends Panel members. The process uses the following steps:
- First, panelists are assigned to the midpoint of the income range they selected in a family income question that was measured on either the most recent annual profile survey or, for newly recruited panelists, their recruitment survey. This provides an approximate income value that can be used in calculations for the adjustment.
- Next, these income values are adjusted for the cost of living in the geographic area where the panelist lives. This is calculated using price indexes published by the U.S. Bureau of Economic Analysis. These indexes, known as Regional Price Parities (RPP), compare the prices of goods and services across all U.S. metropolitan statistical areas as well as non-metro areas with the national average prices for the same goods and services. The most recent available data at the time of the annual profile survey is from 2022. Those who fall outside of metropolitan statistical areas are assigned the overall RPP for their state’s non-metropolitan area.
- Family incomes are further adjusted for the number of people in a household using the methodology from Pew Research Center’s previous work on the American middle class. This is done because a four-person household with an income of say, $50,000, faces a tighter budget constraint than a two-person household with the same income.
- Panelists are then assigned an income tier. “Middle-income” adults are in families with adjusted family incomes that are between two-thirds and double the median adjusted family income for the full ATP at the time of the most recent annual profile survey. The median adjusted family income for the panel is roughly $74,100. Using this median income, the middle-income range is about $49,400 to $148,200. Lower-income families have adjusted incomes less than $49,400 and upper-income families have adjusted incomes greater than $148,200 (all figures expressed in 2023 dollars and scaled to a household size of three). If a panelist did not provide their income and/or their household size, they are assigned “no answer” in the income tier variable.
Two examples of how a given area’s cost-of-living adjustment was calculated are as follows: The Pine Bluff metropolitan area in Arkansas is a relatively inexpensive area, with a price level that is 19.1% less than the national average. The San Francisco-Oakland-Berkeley metropolitan area in California is one of the most expensive areas, with a price level that is 17.9% higher than the national average. Income in the sample is adjusted to make up for this difference. As a result, a family with an income of $40,400 in the Pine Bluff area is as well off financially as a family of the same size with an income of $58,900 in San Francisco.
Analysis of news influencers
Overview
To better understand the news influencers that Americans are getting news from on social media, researchers conducted an in-depth analysis of a sample of news influencers who posted about current events and civic issues on at least one of five major social media sites where news is often discussed: Facebook, Instagram, TikTok, X and YouTube. The analysis looked at personal characteristics of each news influencer as well as their online practices.

For the purposes of this research, news influencers are defined as people who regularly post about current events and civic issues on social media and have at least 100,000 followers on any of Facebook, Instagram, TikTok, X or YouTube. News influencers can be journalists who are affiliated with a news organization or independent content creators, but they must be people and not institutions.
Account collection
Overview
There are very limited lists of news influencers, and few resources to verify those that do exist. Because of this, we compiled our own list of 2,058 news influencers by searching for accounts that regularly used news-related keywords on Facebook, Instagram, TikTok, X and YouTube.
Keyword development
The first step in this process was developing a list of news-related keywords that are relevant to current events and civic issues in the United States. Throughout late 2023 and early 2024, four researchers with expertise in the news media brainstormed related keywords and grouped them into 45 categories ranging from affirmative action to free speech to immigration. Each category had multiple keywords – sometimes dozens.
In order to ensure we were not missing news events as they were occurring, in January 2024, we conducted daily reviews of transcripts of news on CNN, Fox News and MSNBC, as well as news highlights from NewsMax’s YouTube page and a review of Breitbart and Vox’s social media and homepage (to ensure a mix of the key points of discussion across the political spectrum). For the cable news channels, researchers downloaded transcripts from The Internet Archive’s TV Archive for each day in January 2024. Once downloaded, episodes were sent to OpenAI’s GPT-4 model with the instructions:
“You are an AI assistant that helps extract information from text. You will be given a set of transcripts from cable news shows. For each episode, please tell us the main topics that are discussed.”
Each day in January 2024, this team of researchers reviewed each summary statement, along with a manual check of NewsMax’s homepage, YouTube page, and social media; Vox’s homepage and social media; and Breitbart’s homepage and social media to discover major stories and potential related keywords. During the keyword brainstorming process, we searched for these keywords on social media sites to determine the extent to which they were being discussed on social media.
The resulting set of 45 keyword categories plus keywords developed through this daily news review were used on each site, although the keywords were sometimes changed to reflect common practices of the site (such as the tendency to use hashtags) and the tools we used.
Collecting accounts
The general process for collecting accounts was similar across sites. Because automated search capabilities on these sites are limited, we used a set of social media monitoring tools to collect accounts. Once accounts were collected, we filtered for the number of times each account had a post that matched any keywords during the collection period because we wanted to limit the analysis to accounts that were regularly posting about news. The exceptions were TikTok and Instagram, as explained below.
To augment this automated collection, we added influencers who were mentioned in articles about news influencers by prominent news outlets.
This collection process resulted in 3,041,652 accounts across Facebook, Instagram, X and YouTube.
After collection, but before manually visiting any account profiles, we looked at the names of accounts that had terms shared with at least nine other accounts. Those terms included publishing terms like “radio” or “TV” that suggested a news organization, country (e.g., “India”) and place names (e.g., “Boston”), and large institutions like the United Nations (“UN”) or Congress (“Congress”). During this process, two researchers quickly evaluated whether a given account was obviously an organization and not an individual and met to discuss accounts that they disagreed about. A total of 4,566 accounts across Facebook, Instagram, X and YouTube were removed this way.
To develop a list of news influencers on Facebook, we turned to CrowdTangle, a social media marketing tool from Meta (Meta shut down CrowdTangle in August 2024). Only public Facebook pages were considered, not groups or private pages. We added two filters to this collection inside CrowdTangle: The minimum number of page followers needed to be 100,000, and they needed to post primarily in English. Across keywords, we collected 358,186 potential news influencer accounts. We further filtered this to only those accounts that posted about any news-related topic at least 30 times in January 2024 (excluding duplicate posts). This resulted in 7,218 accounts, each of which was manually reviewed.
To develop a list of news influencers on Instagram, we first turned to CrowdTangle, a social media marketing tool from Meta (Meta shut down CrowdTangle in August 2024). We added two filters to this collection inside CrowdTangle: The minimum number of followers needed to be 50,000 (during the consolidation process, that follower threshold was later raised to 100,000) and they needed to post primarily in English. Across keywords, we collected 181,850 potential news influencer accounts. We further filtered this to only those accounts that posted about any topic at least 15 times in January 2024 (excluding duplicate posts; we noticed in testing that the overall rate of posting was lower on Instagram than other sites, so we lowered this threshold). After removing accounts with organization names, we were left with 3,818 accounts, each of which was manually reviewed.
Upon inspection, we realized that several Instagram accounts that we had found in media coverage were not picked up by CrowdTangle. Out of concern for the comprehensiveness of this data, we augmented the list of influencers from CrowdTangle with those from two sources: first, 49 influencers we had found in news articles that CrowdTangle did not pick up, and second, using Modash.io, a social media marketing tool. Because we already had a list of potential news influencers (including the ones we found in news articles), we used Modash’s account relevancy tool, which returns accounts that are similar to any provided account. For each account provided, we collected 45 relevant accounts (or three pages of results). Because there was some overlap between the sets of relevant accounts, this resulted in an additional 2,460 accounts, each of which was manually reviewed.
TikTok
To develop a list of news influencers on TikTok we used Modash.io, a social media marketing tool. Whereas other similar tools provide lists of posts that match a set of keywords, Modash’s search function for TikTok lists accounts that used any of the provided keywords in the last two months, resulting in 55,223 accounts. After filtering for accounts with at least 100,000 followers, we were left with 3,342 accounts, each of which was manually reviewed.
X (formerly Twitter)
To develop a list of news influencers on X, we used Meltwater, a social media marketing and analysis tool that can search the entire X firehose. Meltwater includes some advanced filters, which we used in our collection process, as well as some quirks in how it delivers data. We searched for all English-language posts from January 2024 that used our keywords (including in hashtags) and were from accounts with at least 100,000 followers.
Because Meltwater only lets you download 20,000 posts at a time from its dashboard, we removed retweets and accounts that were known to be politicians, and then limited the time and keyword scope of each search we conducted to be below that 20,000-post threshold whenever possible, and posts were sorted by engagement before downloading. After downloading each post, we used only the account information and the number of posts matching each keyword – none of the other post data was used in analysis. This resulted in 39,618 accounts.
We then limited our analysis to accounts that had at least 30 posts in January and that matched our keywords. After removing accounts with organization names, we were left with 7,803 accounts, each of which was manually reviewed.
YouTube
To develop a list of news influencers on YouTube, we used Meltwater, a social media marketing and analysis tool. Meltwater searches the titles and descriptions of YouTube videos from the last 30 days to match keywords but cannot filter YouTube by language or follower count.
Searching YouTube through Meltwater for our keywords in January 2024 resulted in 2,461,998 accounts. We then limited this set to accounts that used those keywords at least 15 times (a lower number than other sites because we found that most accounts posted less frequently). Then, using the YouTube API, we collected follower counts for each account and filtered out accounts with fewer than 100,000 followers. After removing accounts with organization names, we were left with 3,576 accounts, each of which was manually reviewed.
Account verification and consolidation
After this initial sample was concluded, researchers examined all 28,266 accounts that met our criteria to determine if the account was connected to a news influencer. We operationalized the above definition using several criteria:
- Account must not be connected to an institution or organization
- Politicians were excluded
- Main topic needed to be related to U.S. news about current events or civic issues. We included accounts that broadly discussed international affairs, but excluded accounts that focused on one country – with the exception of accounts focused on the Russia-Ukraine war or the Israel-Hamas war, due to the impact these conflicts have on domestic affairs.
A set of coders was trained to identify accounts that met these criteria using a set of sample accounts from each social media site. Any disagreements were discussed between the coders and lead researcher. Intercoder agreement was measured using Krippendorff’s alpha.
The mean alpha across sites was 0.694, with a minimum of 0.631 (YouTube) and a maximum of 0.755 (X).
- Facebook (0.691)
- Instagram (0.707)
- TikTok (0.687)
- X (0.755)
- YouTube (0.631)
This resulted in a set of 2,534 news influencer accounts.
At this point, researchers had collected a set of accounts connected to potential news influencers. But an individual influencer can have accounts on multiple sites, and they may use different screen names on each site.
Because this study focuses on influencers, not accounts, researchers examined each news influencer account above and connected it to any other accounts that influencer may have (including ones on the same site).
During this step, researchers also verified that each influencer met the criteria to be a news influencer. Upon examining the number of influencers on each site, we determined that we could raise the minimum number of followers for accounts on Instagram to 100,000 to match other sites.
This resulted in a final population of 2,058 news influencers across one or more of these sites, including:
- Facebook – 122 news influencers
- Instagram – 176 news influencers
- TikTok – 300 news influencers
- X (formerly Twitter) – 1,458 news influencers
- YouTube – 207 news influencers
Account sampling
There were vast differences in the number of influencers found on each site, with 122 influencers who had accounts on Facebook and 1,458 news influencers who had accounts on X (formerly Twitter). To account for these differences, and ensure there was a large enough sample size for each site, we sampled 500 influencers using a stratified sampling strategy with five strata, based on the site on which we found the news influencer. Strata were ordered according to the number of influencers, and influencers in smaller strata were removed from later strata so they did not have multiple chances for selection.
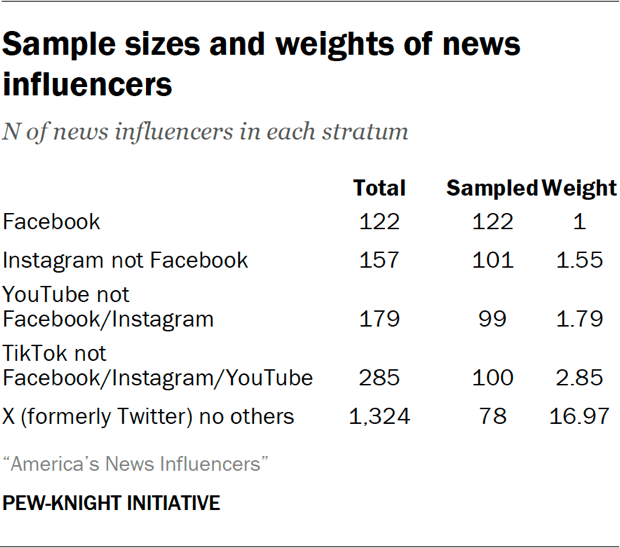
Within each stratum, we sorted influencers by follower count and then selected a set within each stratum using list-based interval sampling. For the remainder of the analysis, each influencer was weighted by the probability of selection; influencers in each stratum were weighted equally because they had an equal chance of selection.
Coding news influencer variables
Once the sample was drawn, a team of coders was trained on a set of variables that analyzed key characteristics of each news influencer.
The first analysis was an inspection of the online practices of the influencer, including the other social media sites they use, whether they host a podcast or offer a newsletter, their interactions with their fans through forums or monetization strategies, and whether they have a news organization affiliation. Coders were trained to find this information only on the news influencer’s social media account profile page (bio, banner image and profile photo, and any pinned post or featured video) and linked personal or professional website (these external links could be available on an influencer’s linktr.ee or similar page). Coders started with the social media account page discovered in the above process and only considered external pages or other social media accounts linked to from that discovered account. Each influencer was coded separately by two researchers, who then met to reconcile any differences.
The second analysis was a more subjective look at each influencer’s personal characteristics: their gender, political orientation and a set of values or identities.
Gender
Researchers attempted to determine each news influencer’s gender by examining how people identify (whether preferred pronouns or other self-descriptions, such as “wife” or “father”) in their social media profiles, personal websites or media coverage. If this information did not yield a result, researchers recorded the gender they perceived the influencer to be based on visual and other cues. While this may not correctly identify the gender of every influencer, the intent of the coding was to capture broad gender patterns among news influencers and not gender identities for individual influencers.
The gender for a small share of news influencers could not be determined; this includes anonymous accounts and accounts run by multiple individuals with different genders (this came up rarely, primarily for accounts connected to podcasts or YouTube shows that were run by two or more co-hosts).
Political orientation
Coders looked at the news influencer’s social media account profile page (bio, banner image and profile photo, and any pinned post or featured video), linked personal and professional websites, and any major news media coverage. For political orientation, we also included each account’s recent posts.
Influencers were categorized by whether they identified with a political party or ideology or expressed support for the Democratic or Republican presidential candidate in their social media profile, posts, personal website or media coverage. People who explicitly identify as conservative, Republican or express support for Donald Trump were categorized as right-leaning, while liberals, Democrats and people who have explicitly expressed support for Joe Biden or Kamala Harris were categorized as left-leaning. Researchers also considered other specific keywords or groups: For example, someone with “MAGA” in their account profile would be categorized as right-leaning, while someone who says they are “progressive” would be coded as left-leaning.
Values/identities
For values and identities, coders only looked at each influencer’s profile page and pinned posts or featured videos, because we wanted to find influencers that make these values and identities a key part of their public persona. These expressions could be made in words, images or emojis, and are often made through emoji flags (e.g., a Palestinian flag, an Israeli flag or a Ukrainian flag).
In these spaces, it is difficult to distinguish between a value and an identity: A rainbow flag, for instance, could be an expression of support for LGBTQ+ rights or a declaration of the influencer’s LGBTQ+ identity. In either case, an account with a rainbow flag would be coded as pro-LGBTQ+.
Intercoder agreement for these variables was measured using Krippendorff’s alpha. The mean alpha across these variables was 0.84, with a minimum of 0.67 (political orientation) and a max of 0.93 (gender and values and identities). Several value/identity variables were found only rarely, so we discussed the examples we saw at length.
Below are the main measures and their alphas (minimum and average reported for variables with multiple, nonexclusive options, like select-alls):
- Gender (0.93)
- Political orientation (0.67)
- Values and identities (min 0.87; average 0.93; max 1.0):
- Pro-abortion rights (1.0)
- Anti-abortion (1.0)
- Pro-LGBTQ+ (1.0)
- Pro-Ukraine (1.0)
- Pro-Russia (not found)
- Pro-Palestine (1.0)
- Pro-Israel (1.0)
- Other (0.87)
Analysis of posts from news influencers
Data collection
To get a better sense of what these news influencers were posting about, we next collected posts from each news influencer across three one-week periods: July 15-21, 2024, which was days after an assassination attempt on then-presidential candidate Donald Trump at one of his rallies, included the Republican National Convention, and ended with President Joe Biden dropping out of the race; July 29-Aug. 4, 2024, during which there was speculation about who Harris would pick as her running mate but few major events; and Aug. 19-25, 2024, which featured the Democratic National Convention.
We collected posts from all five main sites using a set of automated scraping tools. Only original posts and quote posts (on X) were included, not reposts. For each post, the scraping tools provided all information that would appear to a person browsing the user’s profile, including the post’s title (where applicable), text or caption, closed captioning (on YouTube) as well as engagement metrics like the number of likes or shares the post received. These tools also were able to collect reels on Instagram and videos on other sites, but not Instagram stories or other short-term posts. Posts were scraped in August 2024. This resulted in 104,786 posts, across each site:
- Facebook: 16,755 posts
- Instagram: 9,815
- TikTok: 3,514
- X: 67,331
- YouTube: 7,371
Data processing
After this collection process had concluded, we used a series of audio-to-text and video-to-text models to process and transcribe all video posts found on TikTok and Instagram so that we had all text-based data to work with (we were able to download closed captions for YouTube videos). Once these were converted to text, we passed all posts to OpenAI’s GPT-4 model along with an instruction prompt describing our codebook categories to obtain the applicable topic for each post. This was done using the following steps:
- First, audio from video files was extracted and passed to an Audio Spectrogram Transformer model finetuned on the AudioSet dataset. This AST model inputs audio sequences, distinguishes speech from music, and then provides additional labels for the clip using a broad ontology of everyday sound types. For this task, we only used this to identify videos that contained speech.
- For videos where the AST model identified “speech” as the primary audio label, the full audio from the video was then passed to OpenAI’s whisper transcription model. For a balance of accuracy and fast processing time, we used the 769M-parameter “medium” version of this model.
Classifying post topic
Once all TikTok and YouTube videos were transcribed, we turned to the task of categorizing posts by their main topic. Because the volume of this dataset was too large for humans to code, we turned to OpenAI’s GPT-4 model. We provided the model with the full text, including any links that were in the text.
For Instagram and TikTok videos, we provided the caption along with the full transcription. In testing, we found that long YouTube videos were difficult for both humans and GPT to code, so we only provided the transcript of the first approximately 3 minutes of the video. Additionally, when given YouTube videos to code, both humans and GPT were instructed to code based on the video text and then fall back on the video transcript if the topic was not clear from the video text. We added this instruction because we found that YouTubers often open their videos with a long, multisubject introduction that includes topics beyond the primary video topic, which was better indicated by the title. (To see the full prompt and codebook, refer to Appendix D.)
The output of these models was validated in two stages. First, two coders were trained to code posts, including transcripts from video posts, according to an extensive codebook. The Krippendorff’s alpha for this coding was 0.78.
Next, a validation set of approximately 1% set of the full dataset of posts was run through the GPT-4 model (see Appendix D for the full instructions). Coders validated the set of topics and subtopics in the codebook. Across 10 topics, GPT-4 achieved a weighted average F1 score of 0.849, with a minimum of 0.615 and a maximum of 0.895. Across 26 subtopics, GPT achieved a weighted average F1 score of 0.798, with a minimum of 0.323 and a maximum of 0.932. We did not include any topics or subtopics in the analysis below 0.6; these were mostly general categories within a specific topic area.