This study of religious radio in the United States uses three different data sources with accompanying methodologies:
- A nationally representative survey of 5,023 U.S. adults conducted June 9-15, 2025
- An external database of administrative information for all FCC-licensed terrestrial AM and FM radio stations in the U.S.
- A computational content analysis of around 440,000 hours of audio recorded from live radio web broadcasts during July 2025
This is a Pew Research Center report from the Pew-Knight Initiative, a research program funded jointly by The Pew Charitable Trusts and the John S. and James L. Knight Foundation. Find related reports online at https://www.pewresearch.org/pew-knight/.
The American Trends Panel survey methodology
Overview
Data in this report comes from Wave 173 of the American Trends Panel (ATP), Pew Research Center’s nationally representative panel of randomly selected U.S. adults. The survey was conducted June 9-15, 2025. A total of 5,023 panelists responded out of 5,737 who were sampled, for a survey-level response rate of 88%.
The cumulative response rate accounting for nonresponse to the recruitment surveys and attrition is 3%. The break-off rate among panelists who logged on to the survey and completed at least one item is 1%. The margin of sampling error for the full sample of 5,023 respondents is plus or minus 1.6 percentage points.
The survey includes an oversample of non-Hispanic Asian adults in order to provide more precise estimates of the opinions and experiences of this smaller demographic subgroup. Oversampled groups are weighted back to reflect their correct proportions in the population.
SSRS conducted the survey for Pew Research Center via online (n=4,842) and live telephone (n=181) interviewing. Interviews were conducted in both English and Spanish.
To learn more about the ATP, read “About the American Trends Panel.”
Panel recruitment
Since 2018, the ATP has used address-based sampling (ABS) for recruitment. A study cover letter and a pre-incentive are mailed to a stratified, random sample of households selected from the U.S. Postal Service’s Computerized Delivery Sequence File. This Postal Service file has been estimated to cover 90% to 98% of the population.5 Within each sampled household, the adult with the next birthday is selected to participate. Other details of the ABS recruitment protocol have changed over time but are available upon request.6 Prior to 2018, the ATP was recruited using landline and cellphone random-digit-dial surveys administered in English and Spanish.
A national sample of U.S. adults has been recruited to the ATP approximately once per year since 2014. In some years, the recruitment has included additional efforts (known as an “oversample”) to improve the accuracy of data for underrepresented groups. For example, Hispanic adults, Black adults and Asian adults were oversampled in 2019, 2022 and 2023, respectively.
Sample design
The overall target population for this survey was noninstitutionalized persons ages 18 and older living in the United States. It featured a stratified random sample from the ATP in which non-Hispanic Asian adults were selected with certainty. The remaining panelists were sampled at rates designed to ensure that the share of respondents in each stratum is proportional to its share of the U.S. adult population to the greatest extent possible. Respondent weights are adjusted to account for differential probabilities of selection as described in the Weighting section below.
Questionnaire development and testing
The questionnaire was developed by Pew Research Center in consultation with SSRS. The web program used for online respondents was rigorously tested on both PC and mobile devices by the SSRS project team and Pew Research Center researchers. The SSRS project team also populated test data that was analyzed in SPSS to ensure the logic and randomizations were working as intended before launching the survey.
Incentives
All respondents were offered a post-paid incentive for their participation. Respondents could choose to receive the post-paid incentive in the form of a check or gift code to Amazon.com, Target.com or Walmart.com. Incentive amounts ranged from $5 to $20 depending on whether the respondent belongs to a part of the population that is harder or easier to reach. Differential incentive amounts were designed to increase panel survey participation among groups that traditionally have low survey response propensities.
Data collection protocol
The data collection field period for this survey was June 9 to June 15, 2025. Surveys were conducted via self-administered web survey or by live telephone interviewing.
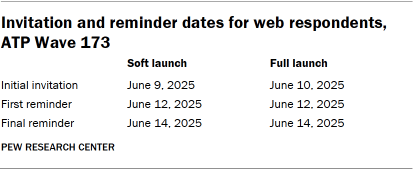
For panelists who take surveys online:7 Postcard notifications were mailed to a subset on June 9.8 Survey invitations were sent out in two separate launches: soft launch and full launch. Sixty panelists were included in the soft launch, which began with an initial invitation sent on June 9. All remaining English- and Spanish-speaking sampled online panelists were included in the full launch and were sent an invitation on June 10.
Panelists participating online were sent an email invitation and up to two email reminders if they did not respond to the survey. ATP panelists who consented to SMS messages were sent an SMS invitation with a link to the survey and up to two SMS reminders.
For panelists who take surveys over the phone with a live interviewer: Prenotification postcards were mailed on June 6. Soft launch took place on June 9 and involved dialing until a total of seven interviews had been completed. All remaining English- and Spanish-speaking sampled phone panelists’ numbers were dialed throughout the remaining field period. Panelists who take surveys via phone can receive up to six calls from trained SSRS interviewers.
Data quality checks
To ensure high-quality data, Center researchers performed data quality checks to identify any respondents showing patterns of satisficing. This includes checking for whether respondents left questions blank at very high rates or always selected the first or last answer presented. As a result of this checking, three ATP respondents were removed from the survey dataset prior to weighting and analysis.
Weighting
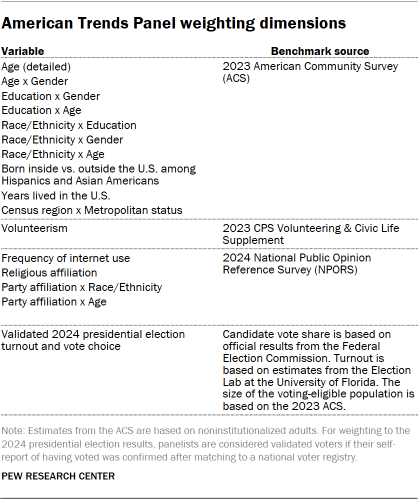
The ATP data is weighted in a process that accounts for multiple stages of sampling and nonresponse that occur at different points in the panel survey process. First, each panelist begins with a base weight that reflects their probability of recruitment into the panel. These weights are then calibrated to align with the population benchmarks in the accompanying table to correct for nonresponse to recruitment surveys and panel attrition. If only a subsample of panelists was invited to participate in the wave, this weight is adjusted to account for any differential probabilities of selection.
Among the panelists who completed the survey, this weight is then calibrated again to align with the population benchmarks identified in the accompanying table and trimmed at the 1st and 99th percentiles to reduce the loss in precision stemming from variance in the weights. Sampling errors and tests of statistical significance take into account the effect of weighting.
The following table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey.

Sample sizes and sampling errors for other subgroups are available upon request. In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Dispositions and response rates


Identifying religious radio stations
To identify the population of religious radio stations broadcasting throughout the United States, we relied on data from Radio-Locator, a vendor specializing in up-to-date administrative data on U.S. and international radio stations. Radio-Locator uses FCC licensing information to maintain a database of terrestrial radio stations, including details such as each station’s location, call sign, band and frequency, and owner or licensee. This station-level data is enriched with additional fields, including each station’s primary genre, website, live audio stream URL and coverage area. For this analysis, we used a snapshot of the Radio-Locator database from March 2025.
The Radio-Locator database contains 25,753 stations located in the 50 U.S. states and the District of Columbia. Of these, 17,115 are primary stations broadcasting on the AM or FM band, and an additional 8,638 are secondary “booster” or “translator” stations that extend or rebroadcast a primary station. In this research, we include booster and translator stations when estimating geographic coverage but filter the data to include only primary stations for the rest of the analysis.
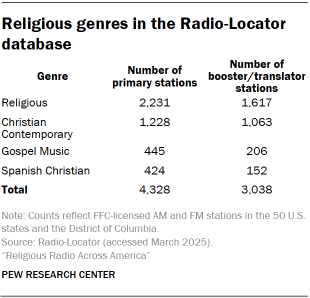
All stations in the Radio-Locator database have been assigned a genre label indicating the type of content that primarily makes up that station’s broadcast schedule. We consider a station “religious” if its content is categorized as Religious, Christian Contemporary, Gospel Music or Spanish Christian. In total, 7,366 such stations appear in the database, 4,328 of which are primary stations included in the main analysis. Stations categorized as Spanish Christian were included in all analyses of administrative data, including geographic coverage, but were excluded from the live radio content analysis.
The population of religious stations was further validated in two ways:
- Researchers reviewed station websites and recorded information about the religious tradition of the station from any available “About us” statements. Read more about how we analyzed stations websites below.
- During the content analysis stage of the study, researchers confirmed that all stations with available recorded content had a non-zero quantity of either spoken content classified under the topic “Religion” or played music by identifiably religious artists. Read more about how we categorized spoken content and identified music below.9
This report focuses on radio stations with primarily religious programming, and at the station level, a large majority of U.S. religious radio is Christian. We encountered just two stations that could be definitively identified as part of a different religious tradition: a low-power FM station in Lakewood, New Jersey, operated by a Jewish organization (WMDI-LP) and an AM station in Spanish Fork, Utah, operated by a Hare Krishna temple (KHQN).
Other religious content may also appear as intermittent programming on other public, talk or community radio stations. However, because these stations do not broadcast religious content as their primary genre of programming, they are not considered for this analysis.
Analysis of station websites
For each of the 3,332 stations with an accessible website (85% of included stations), researchers recorded available information about the station itself, the religious tradition or denomination affiliated with the station and any “About us” statements or similar text.
We also coded the full broadcast schedules of a sample of 300 stations randomly selected from those with both a website and an audio stream URL. Researchers accessed each station’s 24-hour broadcast schedule and divided it into 15-minute time blocks. They recorded program names, host information, program type (talk or music), and start and end times rounded to the nearest 15 minutes.10 Seven days’ worth of scheduling information was collected for each sampled station.
If the broadcast schedule appeared to change week to week or month to month, coders were instructed to input the schedule for the second week of July 2025, if available. If July 2025 was not available, they used the schedule for the current week at the time of coding (April-May 2025).
This process yielded detailed data on the named programs that appear on stations’ published broadcast schedules, which was used to estimate which shows appear across the largest number of stations.
Recording internet broadcasts from religious radio stations
To better understand the content of religious radio broadcasts, we attempted large-scale recording, transcription and analysis of the internet radio streams from 2,083 religious radio stations with primarily English-language content that stream their live broadcasts online. It’s common for a group of individual stations to share the same live broadcast stream, so this set of 2,083 stations is represented by a set of 785 unique web stream URLs.
Sampling time frames to record
For this study, we had the computational capacity to monitor, record and process 250 audio streams simultaneously. Rather than selecting a subset of the population of stations that broadcast online – recording some stations all the time during the data collection window – we recorded in 15-minute time blocks uniformly distributed across all the available web streams – recording all stations some of the time.
Our data collection window was the month of July 2025. We scheduled 250 recording blocks every 15 minutes, 24 hours a day for the entire month. That amounts to 24,000 recordings per day, for a total of 744,000 over the 31 days of July. To maximize coverage within these parameters, in cases where multiple stations shared a single broadcast stream, we included it once (rather than multiple times) in the sampling frame, then assigned recordings from that stream to all stations that shared its URL. On average, each station’s web stream was scheduled for about 237 hours of dedicated recording time during the data collection window.
Recording infrastructure
A note about Educational Media Foundation stations
Educational Media Foundation (EMF) is the largest ownership group in American religious radio, operating both the Air1 and K-LOVE networks of stations. These primarily air Christian music. On-demand online listening is available for both the Air1 and K-LOVE networks. However, these streams are delivered through proprietary web players and mobile applications that do not provide publicly accessible stream URLs that could be reliably integrated into our automated recording system.
Because our recording infrastructure relied on FFmpeg to connect directly to scheduled stream URLs at fixed intervals, we were unable to capture audio from Air1 and K-LOVE stations in a consistent, automated way. As a result, they were excluded from the recorded content collection and subsequent content analysis. They are included in analyses based on administrative data, such as station counts and geographic coverage.
To complete this data collection at the required scale, we developed and deployed a cluster of 250 containerized stream listener applications. Each listener operated using a dedicated schedule, which determined the broadcast stream it connected to during each 15-minute recording time slot. At the beginning of a time slot, the assigned listener would connect to the scheduled URL and process the incoming audio data using the multimedia framework software FFmpeg. After 15 minutes, the listener would disconnect from the stream URL and save the recorded audio file as a low-bit rate (64 kbps) MP3.
Using this procedure, we successfully recorded and processed a total of 716,626 15-minute recordings – 96% of the scheduled time slots we attempted to capture. This represents roughly 230 hours of audio from each distinct web stream URL and totals nearly 440,000 hours of audio once we accounted for multiple stations sharing a web stream.
Speech-to-text transcription
Each recorded audio file was then passed through a machine transcription pipeline which produced line-level transcripts for all spoken content. This pipeline was based on the WhisperX system, which extends basic speech-to-text transcription models with speaker differentiation (diarization) and time stamp alignment. Our implementation of the WhisperX system included:
- whisper-large-v3-turbo transcription models from OpenAI
- speaker-diarization-community-1 diarization/voice activity detection models from pyannoteAI
Our line-level transcripts for each recording not only capture what was said, but also break the conversation up into individual statements or “utterances,” each of which are time-stamped within the audio file and tagged with a speaker ID number to help differentiate between the various voices heard throughout the recording. When transcribed line-by-line like this, the audio collected for this study makes up over 186 million lines of dialogue. An example transcript is included below:
Categorizing spoken content in religious radio recordings
Each approximately 15-minute radio transcript was passed to a large language model (GPT-4.1) to be partitioned into substantively coherent topical segments, rather than relying on fixed time intervals or arbitrary line counts. Because the transcripts were already diarized and line-numbered at the utterance level, the model could evaluate speaker turns and lexical continuity to identify these segment boundaries.
The classifier was instructed to group contiguous utterances into segments that reflected a shared primary format or communicative function (e.g., monologue, interview, news read). Researchers validated the segment breaks throughout the qualitative coding processes. Segment breaks were placed at points where there was a clear shift in subject matter, interactional format or program structure (such as transitions to advertisements, new stories or caller participation). For each resulting segment, the model returned structured metadata, including start and end line numbers and descriptive labels, enabling downstream analyses at the segment level rather than at the raw transcript level.
Read the full prompt we used for this process. The specific classifications created are discussed in more detail below.
Identifying radio segment formats
The first level of classification concerns the segment format. This process identified the basic type of programming occurring in a given segment that contained speaking, and added more specific content labels.
We began by developing a codebook with a number of format categories we expected to find in our audio recordings. These included things like talk programming, news reads, sermons, audience participation and advertisements. Members of the research team then classified a sample of segments. This human coding process involved multiple rounds of iteration where disagreements and edge cases were discussed and the codebook was subsequently updated, until we finalized the format categories as follows:
- Ad/promotion. An advertisement or promotion of a product, service or event.
- Audio drama/narrative. A dramatized production or audio play.
- Caller interaction/audience participation. A host or DJ interacting with listeners. This includes taking calls from the audience and reading audience mail or comments but does not include interaction with program guests.
- Discussion/monologue/commentary. One or more speakers discussing a topic or providing commentary. This includes typical “talk radio” content, banter, religious opinions, and discussions or dialogues between hosts or DJs.
- Interview. An interview with a program guest. This does not include dialogue between station hosts or DJs.
- News read/traffic/weather. Straightforward reads of the news, or local traffic and weather conditions (e.g., “It’s the top of the hour, here’s Bob with the news”). Note that long-form commentary about news or current events is categorized as discussion/monologue/commentary.
- Religious services or sermons. A single speaker preaching or delivering a religious message. This includes prayer, Mass or liturgy.
- Transition/filler. Administrative or logistical announcements, including show introductions, outros, segment transitions or station identification (e.g., “You’re listening to 99.1 FM”).
These format categories are mutually exclusive – that is, each segment could only be assigned to one format category.
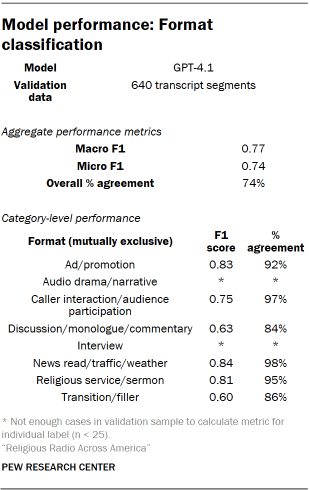
Once the codebook was finalized, it was integrated into the segmentation and processing pipeline and passed to GPT-4.1 for format classification. Read the full prompt we used for this process. A random sample of transcript segments were hand-coded for validation of this task by three researchers. Disagreements were resolved using a Dawid-Skene aggregation model. Performance metrics appear in the table “Model performance: Format classification.”
Named entity recognition
Named entity recognition (NER) is an information extraction task that involves identifying and classifying words or phrases within a longer text that refer to real-world entities. As part of our segmentation and processing pipeline, we instructed a model to perform NER to identify people, groups and places mentioned in the radio segments. We also used NER to flag titles of stories or books (including religious scriptures, such as the Bible) as well as references to specific passages or verses of scripture.
Read the full prompt we used for this process. Specific NER categories and definitions we used were:
- Person. A named individual (e.g., “Donald Trump,” “the Pope,” “Jesus”). This includes both real people and fictional characters, as well as references to deities in a religious context (e.g., “Holy Spirit,” “Heavenly Father”).
- Group. A group of people referred to collectively, but who are not a named organization (e.g., “the congregation,” “the audience”). This includes groups of people referred to by nationality (e.g., “the French”) and religious groups or denominations (e.g., “Catholics,” “Muslims,” “Baptists”).
- Organization. A named organization or agency (e.g., “Pew Research Center,” “NASA,” “the Southern Baptist Convention”).
- Title. A named book, song, film, show, or other piece of art or media (e.g., “The Great Gatsby,” “the Bible”). This includes titles of religious stories (e.g., “The Parable of the Good Samaritan,” “The Sermon on the Mount”). It does not include occupational titles (e.g., “President,” “Doctor,” “Reverend”).
- Place. A named location or geopolitical entity (e.g., “the United States,” “New York,” “Mount Sinai,” “Mar-a-Lago”).
- Scripture reference. A reference to a passage or verse in scripture (e.g., “John 3:16,” “Genesis 1:1”).
To validate the NER results, three researchers reviewed a sample of transcript lines with identified entities and independently coded both the predicted entity name (e.g. “Donald Trump”) and the predicted entity type (e.g. “Person”). Disagreements were resolved using a Dawid-Skene aggregation model. Performance metrics appear in the table “Model performance: Named entity recognition.”

Identifying broad topics
We further classified recording talk segments by the topics mentioned or discussed therein. These labels were intended to reflect general, high-level topical areas so we could broadly categorize the content of religious talk radio.
Similar to the process for determining which formats we would use for categorizing segments, an iterative human coding process was used to determine the final list of topics to identify in the data. Unlike formats, however, topics were not mutually exclusive. A segment could be labeled with as many topics as applicable. The final set of topic categories used was:
- Business/economy/finance. Discussion of economic and financial topics, including tax or tariff policies, personal financial advice, stock markets or investments, and cryptocurrency.
- Entertainment/pop culture/sports. Discussion of pop culture topics including film, television, music, sports and celebrities.
- Family/parenting/education. Discussion of family-related topics including marriage, having children, child care, child-rearing, schools and education standards.
- Health/wellness. Discussion of wellness-related topics including health care, abortion, vaccination, medication, mental health, fitness and exercise.
- Lifestyle/advice/personal development. Direct and prescriptive recommendations for lifestyle, actions or behaviors.
- Politics/current events/social commentary. Discussion of or commentary on topics including news or current events, local updates, politics and policy, and social issues. This does not include community updates or weather/traffic segments that do not touch on broader political or news topics.
- Religion. Discussion of religious topics, including religious beliefs, scripture and religious figures.
- Science/technology. Discussion of science-related topics, including climate change and evolution.
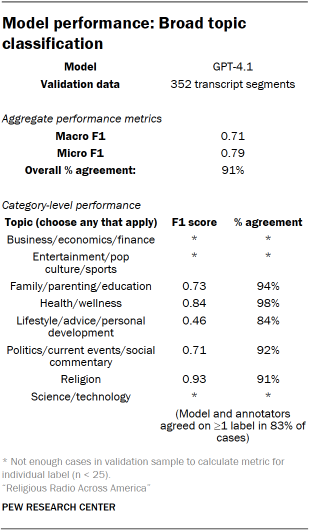
Once the codebook was finalized, it was integrated into the segmentation and processing pipeline and passed to GPT-4.1 for topic classification. Read the full prompt we used for this process. A sample of the model’s predictions for this task were hand coded for validation by three researchers. Disagreements were resolved using a Dawid-Skene aggregation model. Performance metrics appear in the table “Model performance: Broad topic classification.”
Identifying more specific subtopics
Beyond the broader topics that we identified, we further examined specific subtopics of interest. Any segments with a topic label of Religion, Politics/current events/social commentary, Health/wellness, Business/economy/finance or Science/technology were passed to a subtopic model.
Similar to the processes for format and topic categorization, an iterative human coding process was used to determine the final set of subtopics to be identified. Just as with topics, subtopics were not mutually exclusive. A segment could be labeled with as many subtopics as applicable. We defined the final list of topics to as the following:
- Abortion. Faith-based discussions about the morality of abortion, debates between policy positions, discussion of abortion alternatives (e.g., crisis pregnancy centers) or reproductive health clinics that commonly offer abortion procedures, and general references to abortion, even if the term “abortion” is not explicitly mentioned. This also includes discussion of federal laws or court decisions related to abortion rights (e.g., Roe v. Wade, Dobbs v. Jackson Women’s Health) and state laws or abortion bans. This does not include general discussions of women’s health or reproductive health (e.g., IVF, birth control).
- Crime/law enforcement. Discussion of crime, law enforcement and the justice system. This includes references to specific crimes (for example, in a news read or while discussing a high-profile court case), references to crime, crime waves, “law and order” or lawlessness in the abstract, actions taken by police or other law enforcement agencies such as U.S. Immigration and Customs Enforcement, crime or property destruction during protests, and police actions during protests. This does not include discussion of protests more generally (that is, protests not involving crime, property destruction or police actions).
- Economy. Discussion of the economy or economic conditions, including global trade or tariff policy, “kitchen table” issues (e.g., cost of groceries or child care), cost of living, inflation, tax policies, unemployment, hiring or layoffs, poverty, and the stock market. This does not include general references to economic or social class (e.g., “the middle class”).
- Foreign policy/international politics. Discussion of U.S. policy toward other countries, domestic politics within other countries, and international politics between other countries, including global trade or tariff policy, and contemporary wars and conflicts. This does not include discussion of historical wars and conflicts.
- Immigration. Discussion of immigration or immigrants, both in a U.S. context and in a global context. This includes actions of Immigration and Customs Enforcement (ICE) or Customs and Border Patrol (CBP) (e.g., deportation or detention of immigrants), actions of immigrants, and immigration policies.
- LGBTQ issues and rights. Discussion of LGBTQ issues, rights and identities, including related laws or court rulings (e.g. Obergefell v. Hodges), same-sex marriage, the compatibility or incompatibility of religion and LGBTQ identities, issues related to transgender individuals or identities (e.g., the availability of gender-affirming care, bathroom bans, sports bans, etc.), references to conversion therapy, and discussion of homophobic or transphobic rhetoric or actions.
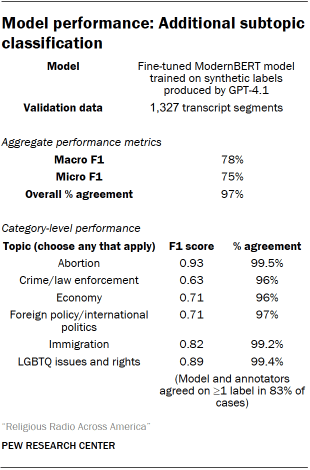
Once the codebook was finalized, we fine-tuned a ModernBERT model on a set of synthetic topic labels generated by GPT-4.1 for a random sample of segments from the broader collection of data. We then used this model to further classify the remaining segments at scale. Read the full prompt we used for this process. A random sample of transcript segments were hand-coded for validation of this task by three researchers. Disagreements were resolved using a Dawid-Skene aggregation model. Performance metrics appear in the table “Model performance: Additional subtopic classification.”
Classifying issue stance
In addition to categorizing segments by detailed subtopic and identifying key individuals and groups mentioned using NER, we also wanted to assess speakers’ attitudes toward a set of key issues. To achieve this, we developed a stance classification system which, given a target issue, could identify whether a text about that issue is neutral or opinionated, and if opinionated, whether the speaker expresses a favorable or unfavorable opinion toward the issue.
We coded stance for a selection of issues, individuals and groups drawn from both our NER process and our subtopic classification process.
- From the NER results, we identified mentions of Donald Trump, Joe Biden, the Democratic Party and the Republican Party. We also used the NER results to identify references to Israel and the Palestinian territories – but only in segments with the Foreign policy/international politics subtopic label, which allowed us to narrow our analysis to opinions about contemporary events in the region rather than discussions related to its biblical context.
- From the subtopic categorizations, we coded stance for five additional issues: abortion, LGBTQ issues and rights, immigration, economy, and crime/law enforcement.
For most of these issues, individuals and groups, we coded segments as neutral or opinionated, and opinionated text was further coded as favorable/unfavorable with respect to the subject. The crime/law enforcement and economy subtopics do not map as cleanly onto specific positions, so these were only coded as neutral or opinionated.
The full set of issues, individuals and groups analyzed for stance was:
- Donald Trump: Neutral coverage includes segments that mention Trump, his actions or the actions of his administration in a factual, value-neutral way. Opinionated coverage includes segments that express a position about Trump, his actions or the actions of his administration. If the speaker indicates that their position is aligned with or supportive of Trump, the segment is coded as favorable. If they express disagreement or criticism, the segment is coded as unfavorable.
- Joe Biden: Neutral coverage includes segments that mention Biden, his actions or the actions of his administration in a factual, value-neutral way, including retrospective references to his presidency. Opinionated coverage includes segments that express a position about Biden, his actions or the actions of his administration. If the speaker indicates that their position is aligned with or supportive of Biden or his administration, the segment is coded as favorable. If they express disagreement or criticism, the segment is coded as unfavorable.
- Republican Party: Neutral coverage includes segments that mention the Republican Party by name and discuss its members, leadership, platform or actions in a factual, value-neutral way. Opinionated coverage includes segments that express a position about the Republican Party, including evaluations of its elected officials, policy positions, electoral performance or broader direction. If the speaker indicates that their position is aligned with or supportive of the Republican Party, the segment is coded as favorable toward the party. If they express disagreement, criticism or disapproval, the segment is coded as unfavorable toward the party.
- Democratic Party: Neutral coverage includes segments that mention the Democratic Party by name and discuss its members, leadership, platform or actions in a factual, value-neutral way. Opinionated coverage includes segments that express a position about the Democratic Party, including evaluations of its elected officials, policy positions, electoral performance or broader direction. If the speaker indicates that their position is aligned with or supportive of the Democratic Party, the segment is coded as favorable toward the party. If they express disagreement, criticism, or disapproval, the segment is coded as unfavorable toward the party.
- Israel: Neutral coverage includes segments that mention Israel, the Israeli government or Israeli actions in a factual, value-neutral way, including descriptions of ongoing hostilities, diplomatic activity or other foreign policy developments. Opinionated coverage includes segments that express a position about Israel or the actions of its government or military, including the conduct ofthe Israel-Hamas war and broader policy questions related to the conflict. If the speaker indicates that their position is aligned with, supportive of or sympathetic toward Israel or its actions, the segment is coded as favorable toward Israel. If the speaker expresses criticism or disapproval of Israel or its actions, the segment is coded as unfavorable toward Israel.
- Palestinian territories: Neutral coverage includes segments that mention the Palestinian territories, governing authorities or the Palestinian people in a factual, value-neutral way, including descriptions of ongoing hostilities, diplomatic activity or other foreign policy developments. Opinionated coverage includes segments that express a position about the Palestinian territories, authorities or the Palestinian people, including the conduct of the Israel-Hamas war and broader policy questions related to the conflict. If the speaker indicates that their position is aligned with, supportive of or sympathetic toward the Palestinian territories or people, the segment is coded as favorable toward the Palestinian territories. If the speaker expresses criticism or disapproval of the Palestinian territories or people, the segment is coded as unfavorable toward the Palestinian territories.
- Abortion: Neutral coverage includes segments that mention abortion, abortion rights, legislation, court cases, ballot initiatives or related medical procedures in a factual, value-neutral way. Opinionated coverage includes segments that express a position on the legality, morality, availability or regulation of abortion, or that advocate for particular abortion policies. If the speaker expresses a position supporting abortion rights or access to abortion, the segment is coded as favorable toward abortion rights. If the speaker expresses a position opposing abortion or supporting restrictions or bans, the segment is coded as unfavorable toward abortion rights.
- LGBTQ issues and rights: Neutral coverage includes segments that mention LGBTQ people, issues, rights, legislation, court cases, public debates or related policies in a factual, value-neutral way. Opinionated coverage includes segments that express a position on LGBTQ rights, legal protections, social acceptance, education policy, gender identity and related policy, or other issues affecting LGBTQ people. If the speaker indicates support for LGBTQ rights, protections or social acceptance, the segment is coded as favorable. If the speaker expresses opposition to LGBTQ rights, advocates for restricting protections or recognition, or frames LGBTQ identities or policies negatively, the segment is coded as unfavorable.
- Immigration: Neutral coverage includes segments that mention immigration, migrants, border crossings, asylum processes, deportations or related policies in a factual, value-neutral way. Opinionated coverage includes segments that express a position on immigration levels, border enforcement, deportation policy, pathways to legal status or citizenship, or the broader social and economic effects of immigration. If the speaker empathizes with immigrant communities or presents immigration as beneficial, desirable, or something that should be maintained or expanded, the segment is coded as favorable. If the speaker presents immigration as harmful, threatening, or something that should be restricted or reduced, the segment is coded as unfavorable.
- Economy: Neutral coverage includes segments that discuss the economy or economic conditions in a factual, value-neutral way. This can include macroeconomic discussions as well as “kitchen table” issues. In opinionated coverage, the speaker takes a position, which could include an opinion on the overall state or direction of the economy, a statement for or against a certain economic policy, or advice about how individual consumers should adapt to economic conditions. (Opinionated coverage of the economy was not further delineated as favorable or unfavorable.)
- Crime/law enforcement: Neutral coverage includes segments that discuss crime, law enforcement or the justice system in a factual, value-neutral way. This can include reporting on specific crimes, descriptions of high-profile court cases, references to crime trends or “law and order” in the abstract, or accounts of actions taken by police, ICE or other law enforcement agencies, including during protests. Opinionated coverage includes segments in which the speaker takes a position on crime rates, the causes of crime, the performance or conduct of law enforcement, the fairness or effectiveness of the justice system, or proposed policy responses to crime. (Opinionated coverage of crime/law enforcement was not further delineated as favorable or unfavorable.)
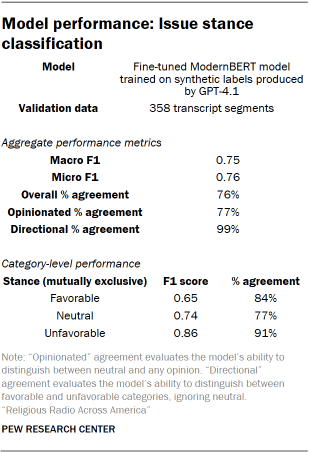
Once the codebook was finalized, we fine-tuned a ModernBERT model on a set of synthetic stance labels generated by GPT-4.1 for a random sample of segments from the broader collection of data. We then used this model to further classify the remaining segments at scale. Read the full prompt we used for this process. A random sample of the production model’s predictions for this task were hand-coded for validation by up to three researchers. Disagreements were resolved using a Dawid-Skene aggregation model. Performance metrics appear in the table “Model performance: Issue stance classification.”
Speaker gender prediction
To estimate the gender of speakers in recorded broadcasts, we used audeering/wav2vec2-large-robust-24-ft-age-gender, a pretrained wav2vec2 model fine-tuned to predict speaker characteristics from vocal audio.
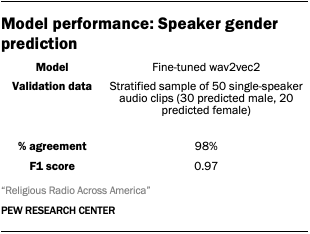
Because our transcription pipeline produces time-stamped transcripts with speaker labels, we were able to identify all the individual utterances for each speaker in a given recording, extract the corresponding audio clip based on these time stamps, and pass the audio segments to the wav2vec2 model. The model generates predictions based on vocal characteristics and outputs a gender classification for each segment. We aggregated these predictions at the speaker level to assign a single gender classification to each speaker in the analysis. This is a probabilistic approach that relies solely on the acoustic features of a speaker’s voice to determine gender and is limited to a binary classification of male/female categories.
To validate the results of the gender prediction model, a researcher coded a stratified random sample of 50 utterances (30 predicted male voices, 20 predicted female) for apparent vocal gender. Their judgement aligned with the model’s in 98% of cases.
Identifying musical content in religious radio recordings
Differentiating music from speech
One of the first steps in processing the raw radio broadcast audio we recorded was to differentiate the segments that were music from those that were spoken content. We did this using MIT/ast-finetuned-audioset-10-10-0.4593, a pretrained Audio Spectrogram Transformer (AST) model fine-tuned on the AudioSet dataset. AudioSet features a wide variety of short audio clips, so we adapted this model to our 15-minute radio recordings by chunking the full recordings into overlapping 10-second segments. All segments were classified as speech or music independently, then merged back together into continuous regions of either category. In cases where the model applied both the speech and music labels (likely indicating someone speaking over music), we considered that segment to be speech.
Independently of this process, all raw audio was being passed through the transcription pipeline discussed above. When the music detection model classified a segment as music, that section of the transcript was notated as <MUSIC> regardless of whether the transcription model attempted to transcribe lyrics.
Identifying tracks, artists and music genres
The approach to speech and music identification outlined above does not differentiate between commercially available studio recordings and other musical elements that might play during the broadcast, including things like advertising jingles, theme music for program intros, and music that plays as part of a religious service. To recognize the specific tracks that played on religious radio stations throughout July 2025, we used AudD, a music recognition API that can analyze a short segment of a song, match it to a track in its database and return metadata about the track, including its artist, genre and identification in the Spotify music library for further details (if applicable).
Rather than attempting to classify all of the musical elements we had collected, we randomly sampled 249,076 of the raw 15-minute recordings we had captured and selected one 12-second clip of music for identification out of the recordings that contained at least two minutes of continuous music.
Using this sampling procedure, 131,825 recordings (53% of those sampled) had identifiable music, totaling 39,262 distinct tracks by 13,594 different artists, and representing 300,915 unique instances of a track playing when we account for the fact that multiple stations share a broadcast stream in many cases. Tracks identified through AudD contained title, artist and album information.
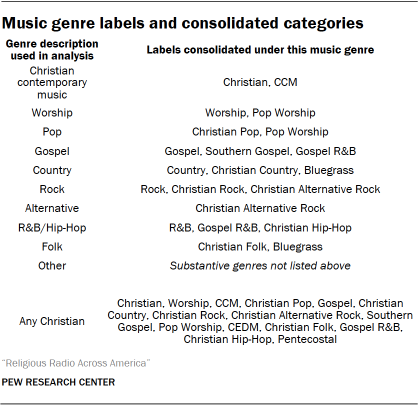
About 93% of all distinct identified tracks also had associated metadata in the Spotify music library, which allowed us to retrieve more detailed information about the artists who created them, including the genres they are associated with if any were listed. Because genre tags are not always standardized across artists within these types of databases, researchers reviewed the top 25 most common genre tags (collectively accounting for 97% of identified tracks that had any associated genre information at all) and merged/unified them into the following set of standardized categories for analysis:
Mapping programming categories onto a 24-hour schedule
The content analysis in this study is based on around 440,000 hours of audio recorded from religious radio stations collected throughout July 2025. As described above, this recording process occurred in 15-minute blocks, uniformly distributed across all the stations we were monitoring. While we captured about 230 combined hours of content per station and have broad coverage of what each station broadcast over the month, what we recorded is not necessarily continuous.
For ease of interpretation, we report various findings that describe the content of religious radio in terms of “hours per day” on a given station or group of stations. But because we don’t have continuous recordings for each station over a 24-hour period, these “hours per day” figures are not measured directly. Instead, they are calculated from the content categories observed in the data. This is a straightforward process: If we observe that half of the material we recorded for a given station is music, then we can multiply that proportion by the 24 hours in a day to arrive at a figure of 12 hours of music per day for that station, on average.
This approach relies on the assumption that the stations in question do, in fact, broadcast 24 hours per day and do not sign off overnight. Our analysis indicates that this is the case for the vast majority of religious stations in America, at least when tuning in via their web streams. We encountered no difficulty recording content overnight during the data collection period.
We also performed a validation check on a sample of 2,500 recordings looking for dead air. We found that on average, a total of less than 30 seconds of silence occurs across an entire 15-minute recording block, and there is no statistically significant difference in the amount of silence heard overnight compared with other times of day. (These tests were performed based on the stations’ local time zones.)





