
This project examines, through a case study model, the question of how media coverage of a current issue in the news relates to public interest in the issue and its relevance to their own lives. It reviews media coverage of the water crisis in Flint, Michigan, from Jan. 5, 2014, to July 2, 2016, and its relationship to trends in public interest in the topic measured by Google search data.1 The study also examines Flint-related conversation on Twitter across the U.S. during this time range.
The search data come from activity on the Google search platform and are grouped at the national level, the Flint DMA level and the Michigan state level. All Google search data were analyzed at the week level. Media coverage included stories about the Flint water crisis identified in national, local and regional news organizations (see media coverage section for more). The public’s response on Twitter included all public tweets across the U.S. that mentioned the issue during the time range studied (see the Twitter section for more).
This project used the private Google Health Application Programming Interface (API) to gather all related data about the Flint water crisis. Pew Research Center applied for and was granted access to use the Google Health API for this study. The Google Health API was launched in 2009 to help researchers detect patterns in searches around the flu as a means for predicting its spread. For a given search term, the Google Health API gives researchers its relative share of all Google searches that were made by individuals within a defined geographic area and time range.
Unlike the private Trends API and public website, which normalize search results in a way that prevents simple comparisons across different geographic regions and time ranges, the Google Health API returns data using a consistent scale. This allows results to be directly compared across time ranges and regions.2 The Google Health API provides data on a daily, weekly and monthly basis. This study uses weekly data and aggregates media and Twitter data on a weekly basis as well.3
All research was conducted by Pew Research Center staff on the original data as provided by the Google Health API. The Center retained control over editorial decisions but consulted with Google data scientists to ensure the search data were interpreted correctly.
Working with large, organic datasets such as these search data requires, at the outset, critical and often complex structural and methodological decisions, as well as a major time investment in data organization and cleaning. Pew Research Center researchers developed a rigorous methodological process to ensure that these data were structured and analyzed to ensure that the results are interpreted accurately. This process is described below.
Search term selection process
Researchers first identified a wide pool of search terms, which they narrowed down to the 10 most relevant. They then used autocomplete to capture the nuances of how users search different topics. Finally, researchers grouped all relevant terms into five broad categories. The sections below discuss each of these elements in detail.
Identifying search terms
The first step in understanding what people were searching for on Google about the Flint water crisis involved identifying the relevant set of queries about the water crisis, some of which may not have used the word “Flint” or even “water.”4 Researchers conducted a number of steps to identify the most comprehensive set of relevant search terms that could sufficiently capture news consumers’ search behavior in relation to the crisis. To start, four researchers brainstormed terms that people might use to search for information about the Flint water crisis or water quality issues in their own areas. Part of this process included identifying terms and phrases that appeared in media coverage. This resulted in the identification of 88 possible search terms (see Appendix for the full list of 88 terms).5
Researchers then narrowed the list by testing each of these terms on Google AdWords and the publicly available Google Trends in order to estimate the popularity of each term and discover any related terms.6 This helped ensure we were not missing any popular search terms related to the crisis or including any relatively rare terms.
The 10 terms that best met these criteria and constitute the base terms used in this study are:
- Flint water
- Tap water
- Water quality
- Lead in water
- Why is my water
- Lead testing
- Water pollution
- Water contamination
- Brown water
- Drinking water
While useful in limiting to searches relevant to Flint or water issues, these are broad terms that do not allow for a nuanced look into the different motivations for people’s search patterns, such as whether search users are seeking news or information about the water quality of their homes. To capture this nuance, three coders used Google’s autocomplete feature on these 10 base terms. Autocomplete is a feature of Google search that provides search suggestions in the form of additional terms that are often searched alongside the terms already entered.7 For instance, “crisis” may be frequently searched with “Flint water,” so Google may suggest “Flint water crisis” as a potential search. Autocomplete results are predictions based on the searcher’s location and previous search history as well as how frequently and recently related terms have been searched by other Google users. Because of these considerations, we used the following process to ensure the most comprehensive and unbiased results.
First, to prevent results from being influenced by their own personal search habits and browser history, coders logged out of their Google accounts and searched using Google Chrome’s “incognito mode.” Second, to provide a more complete list of words, coders turned off Google Instant results. This increased the number of autosuggested results from four to 10. In running the search queries, coders entered each of the separate base phrases and recorded the additional suggestions that appeared. The first search used only the base phrase. Subsequent searches used the base phrase plus a letter of the alphabet, cycling through the letters A to Z. For example, for “Flint water,” coders first searched the base phrase “Flint water” alone and recorded the results. Then, they searched “Flint water a,” followed by “Flint water b” and so on until they had searched the phrase with all letters through Z. This produced a list of 3,428 potential search terms.8 Since it is very difficult to eliminate location identification from one’s search results, this process allowed researchers to generate a large enough pool of results for location bias to be minimized, greatly expanding the number of suggested results beyond those deemed by Google’s algorithm to be most relevant to results found when searching from Pew Research Center’s offices in Washington, D.C.
Researchers then pruned this list by evaluating which combined terms were relevant (e.g., “Flint water crisis news”) and which were clearly not (e.g., “Flint water creek Oklahoma”). The protocol below was followed in order to identify irrelevant terms. Irrelevant terms were those related to the following:
- Jobs and other employment opportunities
- Parks, creeks and zoos
- Utilities and other council matters
- Water level and river floodings
- International incidents for water (for example Flint in Yorkshire, UK)
- Informational terms about water not related to the crisis (for example, definitions of water and aquariums)
- Celebrities that did not relate to the water crisis or water issues
- Photography terms
- Trade associations and conferences about water
- School notes, tests, lesson plans and other material
- Inappropriate and graphic language
- Household terms: cleaning, leaks, breakdowns, pressure, laundry, refrigerator
- Water pollution not related to drinking water (for example, pollution of sea water and marine life)
- Sports-related terms
Finally, researchers simplified the terms by removing the following elements:
- Prepositions and articles such as in, on, at, from, of, by, and, or, the, a, an, etc.
- Connecting words such as vs, versus, between, among, etc.
- Redundant terms that appeared in the autocomplete, e.g., the base term “lead testing” with the autocomplete term “lead hair loss” became “lead testing hair loss”
- Conjugates of the verb “to be” (e.g., is, was, were), with the exception of the base “why is my water”
- Question words from autocompletes such as what, why, when, however, etc. (“why is my water” base remained)
- Personal pronouns, e.g., you, me, I, we, their, etc.
- Adverbs, e.g., especially, mainly, etc.
Search terms were only altered when doing so did not change the meaning of the term. Therefore, adverbs, pronouns or question words were not removed if the meaning of the term was different after the removal. This resulted in some duplicate terms, which were removed.
Through these processes, researchers identified 735 irrelevant or duplicate terms from the categories above and removed them from the analysis.
Additionally, researchers conjugated each verb in the term list and pluralized (or singularized) nouns. For example, for the term “test” we added the conjugations “tested” and “testing” and the pluralized noun “tests.”9
Final search terms and categories
The final step included the categorization of all the related terms into five conceptually distinct groupings, which allowed researchers to study and analyze search activity in a more straightforward way. Grouping all related search terms into five categories allowed for more comprehensive results. This also allowed researchers to address the sparsity inherent in data on individual terms. Two researchers categorized all terms. When the two researchers disagreed on a term’s category, a third researcher also evaluated the term and made a final coding decision. Terms that could not be categorized into any of the categories below were excluded from the analysis.
The five search term categories are the following:
- Public health and environment (557 terms)
- Personal health and household (692 terms)
- Chemical and biological contaminants (135 terms)
- Politics and government (344 terms)
- News and media (965 terms)
To avoid repeating results, researchers manually reviewed and removed search terms within the same category that were likely to produce redundant results. For instance, the results for the term “water contamination Flint Michigan” would be included in the results for “water contamination Michigan” (order of terms does not matter). Researchers de-duplicated the search terms by removing all terms whose results would already be included in another term of the same category, leaving only the shortest and most inclusive term.
This process resulted in a final term list of 2,693 terms in total. All terms in a category were combined into a single set of searches using Boolean logic. This allowed us to request unduplicated search volume for each of the five topic categories.
Google search sampling process and data structure
Researchers subjected the Google Health API to extensive testing and consulted with experts at Google News Lab to design a data collection process for this study. This process is described below.
Google Health API sampling
All data returned from Google’s Health API is the result of a multistage sampling process.
First, the Google Health API gathers a random sample of all Google searches that is anonymized and placed in a database, which researchers can then query. For each query, the researcher specifies a set of search terms (e.g. “Flint water lead testing”), a geographic region (e.g. Michigan),10 a time range and an interval. For this study, all queries used the time range Jan. 5, 2014, to July 2, 2016, and a weekly interval. When a researcher sends this query to the Google Health API, the system takes a second random sample of all searches in the anonymized database that matches the chosen geography and time range. The relative share of searches that match the chosen search terms is calculated using this second sample. Each time a sample is drawn for a query, it is cached for approximately 24 hours. As a result, repeated requests to the API for the same query within that 24 hour range will return the same results. However, after 24 hours, the cache is deleted, so a new request to the API with that same query will force the API to draw a new sample, and the results will change slightly because of sampling error.
Using the sample of searches produced in response to each query, the Google Health API then calculates the proportion of searches that match the selected terms for each specified interval in the time range. For instance, if the query is for the term “Flint water lead testing” in Michigan from Dec. 6, 2015, through March 5, 2016, at a weekly interval, it separately calculates the proportion of searches in each week pertaining to “Flint water lead testing.” These proportions are then scaled by a constant multiplier.11 In simple mathematical terms:
Result = (number of searches for matching terms/total number of searches) x multiplier
Additionally, if the share of searches for a term inside a given interval is below a certain threshold, Google Health API returns a result of zero. This is done to protect the privacy of individual users and to ensure that they cannot be identified.
The fact that the measure is a rescaled proportion of searches in a region/interval has two important implications for research. First, it is not possible to compare the absolute number of searches for a given term, as researchers only know the proportion of matching searches and not the total volume. Second, it is only possible to compare the relative proportion of searches across time intervals and geographies. For example, the graphic below shows the trends for “Flint water lead testing” in the United States as well as in just Michigan. In this case, the term “Flint water lead testing,” makes up a larger proportion of searches in Michigan than in the U.S. overall.
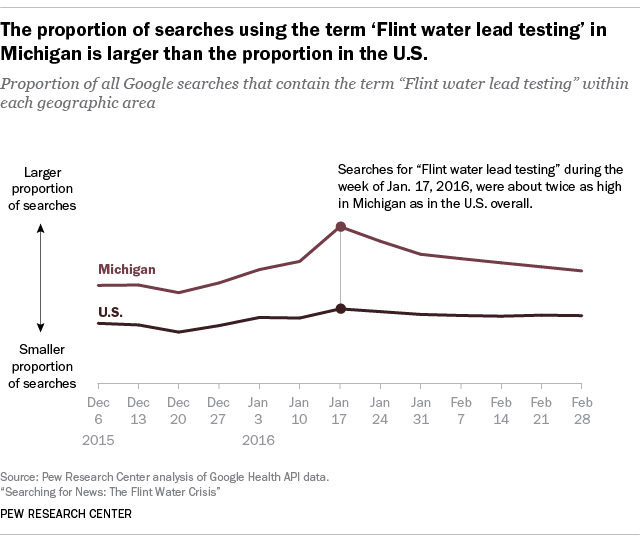
These results do not indicate that the total number of searches from the week starting on Dec. 6, 2015, through the week of Feb. 28, 2016, was higher in Michigan than in the rest of the country, just that a higher proportion of searches in Michigan matched the search term “Flint water lead testing” than the proportion of matching searches across the entire U.S. Furthermore, these data do not indicate the actual percentages of searches for “Flint water lead testing” in either Michigan or the U.S. Rather, we only know that the share of all searches that used the term “Flint water lead testing” during the week of Jan. 17, 2016, was about twice as high in Michigan as in the U.S. overall.
Google search data collection and cleaning
The dataset used for this report consists of week-to-week trends in the relative proportion of searches belonging to five term categories: Public health and environment; personal health and household; chemical and biological contaminants; politics and government; and news and media – in the Flint DMA, the state of Michigan and the entire U.S. for the time range of Jan. 5, 2014, to July 2, 2016.
Because the sample of searches used to calculate results for a query is only cached for 24 hours, results will be different depending on the day the query is made. As a result, Google Health API results are subject to sampling error analogous to public opinion surveys. To reduce the effect of this sampling variability, we obtained the results of 50 queries for every value used in the analysis, with each query coming from an independent sample generated after the previous day’s sample had expired.
To collect multiple samples every day without waiting for the Google cache to refresh every 24 hours, we employed a “rolling window” method that changed the time range of each request. Each call to the API requested a window five intervals long, with each subsequent window overlapping the previous window for all but the first interval. For instance, a rolling window of two weeks across a two-month sample would first request weeks 1-2, then weeks 2-3, then weeks 3-4, etc., until all weeks were sampled exhaustively.12 Consequently, researchers collected five samples per day for each interval, time range and search term.
In addition, researchers used four different Google accounts to access the API, as each account has a daily limit of 5,000 queries. This allowed researchers to collect at least 50 samples over about three weeks for all the term groupings and the three geographies studied.
Because of the privacy threshold described above, the values for some weeks were returned as zeros in some (but not all) of the 50 samples when the number of searches in the category was very low. These zero values were removed and imputed in order to avoid bias that would result from either excluding them or treating them as if their true values were zero. This was done by first ranking all nonzero values from a given week from lowest to highest and assigning each one the value of its corresponding theoretical quantile from a log-normal distribution. Zeros were then replaced with predicted values from a regression model fit to the nonzero samples. All samples in a geography/category pair were imputed simultaneously using a multilevel regression model with a random effect for the week of the sample.13
Once the zero values had been imputed, the final value for each week was calculated by taking the average across all 50 samples.
Google search data analysis
The main goal in this analysis was to identify shifts in search patterns that indicated a substantively meaningful change in the public’s search behavior. However, this was complicated by considerable noise, as the values could fluctuate from week to week even as the trend remained constant. In some instances, there were large week-to-week spikes in search, making changes easy to identify. In other cases, the level of search activity changed more gradually. The research team was interested in identifying both types of change.
We make three types of comparisons in this project, each of which involves different considerations:
- Comparison within a category from one interval (week) to another. In this instance, we are trying to determine if a week-to-week change is meaningful.
- Comparison between categories in a given time range. For example, we may want to compare search activity about news-related terms with search activity about political terms for a given week or set of weeks (e.g., during the main time of attention in early 2016).
- Comparison among regions. This would compare attention for instance between searches about politics in Michigan and searches about politics in the U.S.
Trend line smoothing
To help distinguish between meaningful change and noise, researchers used a smoothing technique called a generalized additive model (GAM). A GAM with 50 degrees of freedom was fit to the trend for each combination of region and category using the gam package on the R statistical software platform. The number of degrees of freedom was chosen by the researchers because it successfully eliminated small, week-to-week fluctuations from the trend lines while retaining both gradual trends and large, sudden spikes. The smoothed data were used in subsequent analyses and all graphics shown throughout the study.
Changepoint method
A second statistical technique called binary segmentation changepoint analysis14 was used to identify periods during which attention was greater or lower than during the neighboring periods. The analysis was performed using the changepoint package for the R statistical computing platform. Changepoint analysis was performed on both imputed and smoothed data (as defined above) to validate results.
The changepoint model identifies those weeks in which search volume increased or decreased significantly from the prior period. Accordingly, the changepoint model breaks up a timeline into discrete sections, each of which exhibits search behavior that is qualitatively different from that of neighboring sections. It represents a meaningful change in search patterns relative to prior periods.15 Despite this, several categories, such as contaminants at the national level, produced sections that only minimally differed from neighboring sections. To ensure that the final analysis did not include periods that are not meaningfully distinct, researchers examined the difference between the peak values for neighboring periods. After examining the distribution of these peak-to-peak differences across all regions/categories, analysis was further restricted to only those periods where the size of the peak-to-peak difference was at least 30% of the mean value for the previous period.
Media coverage data
This analysis also compared the ebb and flow of searches with the ebb and flow of news coverage about the Flint water crisis – both nationally and locally/regionally. The goal of this part of the project is to capture broad media coverage volume over time and not pursue a detailed media content analysis. Content was collected for the same time range as search data: from Jan. 5, 2014, to July 2, 2016.
Sample design
The news coverage dataset included content that could be identified as being about the Flint water crisis from a sample of local/regional and national news media. This included national newspapers, network TV, local newspapers and MLive.com, a digital outlet covering news in Michigan. The national newspapers selected here represent the five newspapers with the highest circulation in the U.S., according to Alliance for Audited Media (AAM). For network TV, evening newscasts were selected as they receive the highest average overall combined viewership among all daily network news programming. The three local daily newspapers used are the highest-circulation daily papers in Flint and Detroit, according to AAM. Five weekly and alt-weekly newspapers in Flint and Detroit with paid circulation were identified using lists from Editor & Publisher 2015 Newspaper Weeklies Databook.16
National newspapers
- The New York Times
- USA Today
- The Washington Post
- Los Angeles Times
- The Wall Street Journal
Network TV
- ABC evening newscast
- CBS evening newscast
- NBC evening newscast
Local newspapers (daily)
- Flint Journal
- Detroit Free Press
- Detroit News
Local newspapers (weekly and alt-weekly)
- The Burton View
- Grand Blanc View
- Detroit Metro Times
- Michigan Chronicle
- Hometown Life17
Local digital outlets
- MLive.com
Collection of national newspaper content
The national news outlets studied here were: USA Today, The New York Times, The Washington Post, Los Angeles Times and The Wall Street Journal. All of these newspapers were accessed through the LexisNexis database except The Wall Street Journal, which was accessed through the ProQuest News and Newspapers database.
To find all relevant content, three coders searched the aforementioned databases. For articles in the LexisNexis database, coders used the search term “Flint w/5 water,” which produced results for all articles featuring the word “water” within five words of the word “Flint.” For articles in the ProQuest News and Newspapers database, coders used the search term “Flint near/5 water,” which also produces results for articles featuring the word “water” within five words of the word “Flint.”
Collection of national TV content
For national network TV coverage, three coders collected transcripts of episodes of the evening newscasts of ABC, NBC and CBS through the LexisNexis database using the search term “Flint w/5 water,” “Michigan w/5 water,” “Snyder w/5 water” and “lead w/5 poisoning.” For comparison, a research analyst searched the Internet Archive’s TV News Archive using the search term “Flint.” An additional search was conducted for transcripts about Flint using the search term “Flint AND (lead OR water)” to ensure all identifiable content was captured.
The results of the transcript searches were compared with the results of the TV News Archive search. Many of the transcripts that resulted from these searches were incomplete, so a coder matched the transcripts to video segments for each newscast. In this process, story segments about Flint were distinguished from teasers. This resulted in 77 video segments of stories about Flint and 81 full transcripts of evening news programs featuring a segment about Flint. In the end, the full transcripts of the evening newscasts were used for analysis. The final dataset therefore included 81 TV news transcripts: 27 from NBC, 23 from ABC and 31 from CBS.
Collection of local content
For local coverage, stories were collected from daily, weekly and alt-weekly newspapers in the Flint and Detroit regions. The Flint Journal and The Detroit News were accessed using the LexisNexis database while the Detroit Free Press was accessed using the ProQuest News and Newspapers database.
Two weekly newspapers were identified in Flint: The Burton View and Grand Blanc View. Researchers identified The Michigan Chronicle and Hometown Life (a group of suburban newspapers housed under the same website) as Detroit area weeklies. One alt-weekly newspaper, Detroit Metro Times, was also included. Coders searched each individual site for stories about the Flint water crisis between Jan. 5, 2014, and July 2, 2016, using the search term “Flint water.”
MLive.com is the digital portal for a regional Michigan media group that publishes The Flint Journal and seven other newspapers in Michigan. As such, it houses journalistic content for both Flint and the broader region.
Relevant content from MLive.com was collected using a Google site search on the website for the term “Flint water” between Jan. 5, 2014, and July 2, 2016. Many of these articles also appeared in the print edition of The Flint Journal (often, stories appeared on MLive.com first and then were published as part of the next issue of The Flint Journal). These duplicate stories were removed from the dataset. The remaining articles were then validated to be about the water crisis, and letters to the editor and other materials that were not articles were removed. The final dataset included 1,065 articles from MLive.com.
Local television newscasts from the Flint DMA were not included in this study. Archives of local newscast content are nearly impossible to obtain, as no industry-wide historical database exists and very few stations archive broadcast programming on their websites. However, internal research conducted by Pew Research Center has found that, where available, local TV affiliates’ websites largely mirror their broadcasts. To determine if the rate of coverage differed from other local media included in this study, researchers first conducted a Google site search on each of the Local TV affiliates’ websites in the Flint DMA (abc12.com, nbc25news.com, wsmh.com, wnem.com) for the terms “flint” and “water” between Jan. 5, 2014, and July 2, 2016. In addition, each website was reviewed for relevant stories, some of which were included in separate sections dedicated to the Flint water crisis. Researchers found stories about the Flint water crisis across the entire time range studied on just two affiliates’ websites. For these, the larger pattern of attention did not differ from that of the local and regional news media included in this study.
Additional search terms for media content
Across all content types, researchers did an additional search for coverage of the Flint water crisis using the search terms “Michigan w/5 water,” “Snyder w/5 water” and “lead w/5 poisoning” for the LexisNexis database; “Michigan near/5 water,” “Snyder near/5 water” and “lead near/5 water” for the ProQuest News and Newspapers database; and “Michigan water,” “Snyder water” and “lead poisoning” for site searches. This was done to ensure that any stories about water quality issues that were not included in the earlier search were included.
Story selection and validation process
To validate search terms, a codebook was created to determine whether collected stories were relevant to the Flint water crisis. A story was coded as relevant if it contained a specific mention of the Flint water crisis in the body of the story. Stories that were not relevant to the water crisis in Flint were coded as irrelevant. Letters to the editor and headline roundups were also excluded during this validation.
Through this validation process, coders categorized 120 articles as irrelevant.
The final total count of stories in which the Flint water crisis is a hook or focus is 4,451.
- Local daily newspapers: 2,307 stories
- National newspapers: 694 stories
- Network evening news: 81 segments
- Local weekly and alt-weekly newspapers: 304 stories
- MLive.com: 1,065 stories
Twitter data
Researchers analyzed the Twitter discussions surrounding the Flint water crisis using automated coding software developed by Crimson Hexagon (CH). The time range examined was the same as in the other datasets – Jan. 5, 2014, to July 2, 2016.
Crimson Hexagon is a software platform that identifies statistical patterns in words used in online texts. Researchers entered the terms “Flint” and “water” using Boolean search logic and the software identified the relevant tweets. Pew Research Center drew its analysis sample from all public Twitter posts.
This analysis included all public, English-language tweets across the U.S. that included the terms “Flint” and “water” during the time range examined. There were 2.2 million such tweets.
For a more in-depth explanation on how Crimson Hexagon’s technology works click here.
Appendix
This is the full list of the 88 original terms identified.
- “Flint water crisis”
- “lead pipes”
- lead water
- lead in water
- “lead poisoning”
- Flint lead
- Flint lead water
- Flint water
- Flint Michigan lead
- Flint Michigan water
- Flint lead poisoning
- effects of lead poisoning
- lead poisoning effects
- lead poisoning treatment
- lead poisoning symptoms
- lead poisoning signs
- Michigan lead poisoning
- “Rick Snyder” lead
- “Rick Snyder” water
- lead testing
- lead water test
- lead test kit
- lead testing kit
- lead water pipes
- lead water filter
- lead Detroit
- lead risk
- Flint crisis
- Michigan water crisis
- Michigan lead water
- Snyder flint water
- Flint water news
- Flint water facts
- cloudy tap water
- brown tap water
- cloudy drinking water
- brown drinking water
- tap water pollution
- drinking water pollution
- tap water contamination
- drinking water contamination
- flint river water
- flint river polluted
- flint river drinking
- flint river tap
- EPA testing water
- EPA testing tap
- lead levels my water
- lead levels local water
- children water
- water safe
- water quality
- fracking water
- fracking tap
- fracking drinking
- natural gas water
- natural gas tap
- natural gas drinking
- drilling water pollution
- drilling water contamination
- fracking well water
- methane water
- methane tap
- methane drinking
- [name of state environmental agency] water
- benzene water
- benzene tap
- benzene drinking
- lead level dangerous
- methane level dangerous
- benzene level dangerous
- why is my tap water dirty
- drinking water safe
- tap water safe
- tap water sick
- tap water OK
- drinking water germs
- tap water germs
- water OK to drink
- [local area] water safe
- [local area] water OK
- [local area] water lead
- [local area] water germs
- [local area] water cloudy
- [local area] water brown
- [local area] water dirty
- [local area] water contaminated
- [local area] water pollution





