
Survey data in this report are based on Pew Research Center surveys conducted with a nationally representative sample of Hispanics.
Differences between groups or subgroups, such as foreign-born and U.S.-born Hispanics, are described in this report only when the differences are statistically significant and therefore unlikely to occur by chance. The variability of estimates (and thus the margins of error) are computed using techniques that take into account the complex sampling design and weighting method used in the study.
2013 Survey of Hispanics
The nationally representative survey of Hispanics was conducted by telephone (cellphones and landlines) in English and Spanish with 5,103 Hispanic adults, ages 18 and older, living in the United States. The sample was drawn from all 50 states and the District of Columbia, and survey interviews were conducted from May 24 to July 28, 2013. Interviews were conducted for the Pew Research Center by Social Science Research Solutions (SSRS) with a staff of bilingual interviewers.
The survey used a stratified sampling design with oversampling (i.e., geographic-based disproportionate sampling) in areas with a higher incidence of Latinos overall and also in areas with a higher incidence of non-Mexican Latinos. In addition, the survey design included an oversample of non-Catholic Latinos to facilitate analysis of religious groups. The results are weighted to account for the complex survey design, including a correction for oversampling and other differences in the probability of selection as well as sample balancing to population totals for the U.S. Latino adult population. After taking into account the complex sample design, the margin of sampling error for the full sample is plus or minus 2.1 percentage points at the 95% level of confidence.
Eligibility and Bilingual Interviewing
All people ages 18 or older who identified themselves as of Latino origin or descent were eligible to complete the survey. SSRS used a staff of Spanish-speaking interviewers who, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or English. A total of 2,725 respondents (53%) were surveyed in Spanish, and 2,378 respondents (47%) were interviewed in English.
Sampling Error
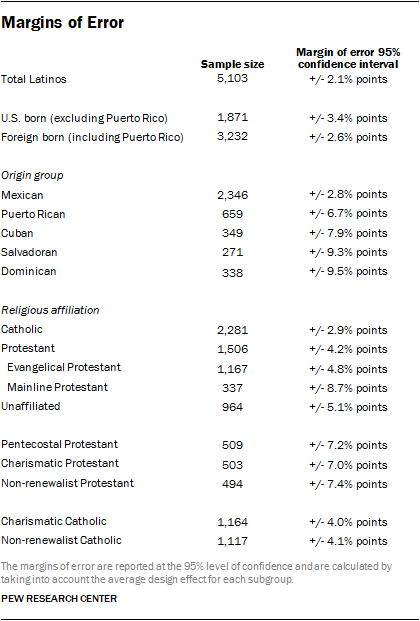
The accompanying table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different subgroups in the survey after taking into account the complex sample design.
The survey’s margin of sampling error is the largest 95% confidence interval for any estimated proportion. For example, the margin of error for the entire sample is ±2.1 percentage points. This means that in 95 out of every 100 samples drawn using the same methodology, estimated proportions based on the entire sample will be no more than 2.1 percentage points away from their true values in the population.
Sampling errors and statistical tests of significance used in this report take into account the effect of weighting. One should bear in mind that, in addition to sampling error, question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Questionnaire Design and Translation
Pew Research Center staff developed the questionnaire in consultation with SSRS staff. The questionnaire covered a range of topics, including Hispanics’ religious affiliation and behaviors, views of Hispanic identity and views about social issues. A pretest of the questionnaire, to inform questionnaire design, was conducted on May 21, 2013, with eight landline and 28 cellphone interviews. The questionnaire was translated into Spanish by staff at SSRS; all translations were reviewed by at least two Pew Research Center staff fluent in Spanish.
To allow for a direct comparison of religious affiliation over time, the survey asked two separate versions of a question about religious affiliation. Respondents in the main study sampling frame (not including the oversample of non-Catholics) were randomly assigned to one of the two questions about their religious affiliation. Different question wording leads to some differences in the proportion of Latinos identifying with religious groups. A comparison of the composition of Catholics, evangelical Protestants and the religiously unaffiliated using each question wording, however, found no or few significant differences. This analysis tested for differences on gender, age and education, as well as on the salience of religion, frequency of worship service attendance, frequency of prayer and an index combining these measures of religious commitment. The results in this report combine those answering both versions of the question about religious affiliation, except where noted in the report, specifically in the analysis of religious affiliation over time and the current religious affiliation of Hispanics.
Survey Administration
All interviews were conducted using a Computer Assisted Telephone Interviewing (CATI) system, which ensures that questions are asked in the proper sequence with appropriate skip patterns. CATI also allows certain questions and answer choices to be rotated, eliminating potential biases from the sequencing of questions or answers.
Both the landline and cellphone samples were released for interviewing in replicates, which are small random samples of each larger sample. Using replicates to control the release of the telephone numbers ensures that the complete call procedures are followed for all numbers dialed.
An average of seven attempts were made to contact each sampled telephone number. Non-responsive numbers were contacted multiple times and at varying times of the day and days of the week to maximize the chance of making contact with a potential respondent. One attempt was made to convert soft refusals. The study included a $5 incentive for any cellphone respondent who requested compensation for their time.
Sample Design
To ensure the highest possible coverage of the eligible population, the study employed a dual-frame landline/cellphone design. The sample consisted of a landline sampling frame (yielding 2,698 completed interviews) and a cellphone sampling frame (2,405 interviews).23 Both the landline and cellphone sampling frames used a stratified sampling design, oversampling areas with higher densities of Latino residents. The same sampling plan was used for the main sample and the non-Catholic oversample.
For the landline sampling frame, the sample was compared with InfoUSA and other household databases, and phone numbers associated with households that included persons with known Latino surnames were subdivided into a surname stratum. The remaining unmatched and unlisted landline sample was divided into the following mutually exclusive strata, based on U.S. Census estimates of the density of the Latino population in each: very high, high and medium Latino.24 These strata were then further subdivided into low Mexican and high Mexican strata.
It is important to note that the existence of a surname stratum does not mean the survey was a surname sample design. The sample was a random digit dial (RDD) sample, with the randomly selected telephone numbers divided by whether or not they were found to be associated with a Spanish surname. This was done simply to improve the efficiency of interviewing respondents in this population.
Marketing System Group’s (MSG) GENESYS sample generation system was used to generate the cellphone sample, which was divided into high and medium Latino strata. These were then further divided into low Mexican and high Mexican strata.
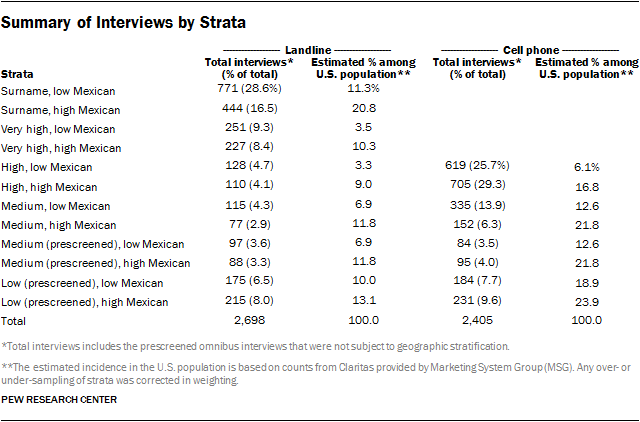
Samples for the low-incidence landline and low-incidence cellphone strata were drawn from previously interviewed respondents in SSRS’s weekly dual-frame Excel omnibus survey. Respondents who indicated they were Latino on the omnibus survey were eligible to be re-contacted for this Pew Research Center survey. In addition, the incidences in the medium landline and cellphone strata were lower than anticipated, so interviews with Latinos prescreened from the Excel omnibus survey were used to gather additional interviews in these strata. This resulted in a total of two additional strata for both the landline and cellphone sampling frames. The number of interviews completed in each stratum is shown in the table below.
The landline response rate was 20.7% for the main study and 24.7% for the oversample, for an overall landline response rate of 22.0%, using AAPOR’s RR3 formula. The cellphone response rate was 14.1% for the main study and 18.2% for the oversample, for an overall cellphone response rate of 14.9%. The overall response rate for the full sample was 19.4%.
Weighting
Several stages of statistical adjustment, or weighting, were used to account for the complex nature of the sample design and ensure an accurate representation of the national Hispanic population. The weights account for numerous factors, including (1) the geographic-based disproportionate sampling of telephone exchanges in both the landline and cellphone RDD frames; (2) a propensity weight adjustment for the potential bias associated with re-contacting previously interviewed respondents in certain strata; (3) an adjustment for unequal probability of selection for those found to possess both a landline and a cellphone; and (4) an adjustment for the likelihood of within household selection in the landline sampling frame.
In addition, the data were put through a post-stratification sample balancing routine to population totals for the U.S. Hispanic adult population based on the 2012 U.S. Census Bureau’s Current Population Survey, March Supplement. Iterative proportional fitting technique, or raking, corrects for differential nonresponse that is related to particular demographic characteristics of the sample. This weight ensures that the demographic characteristics of the sample closely approximate the demographic characteristics of the population. Prior to raking, the base weights were trimmed to control the variance created by the base weight from 0.10 to just over 5.0. The variables matched to population parameters were: age by state (California, Florida, New York, Texas and all other states combined), gender by state, heritage by state, education by state, U.S. born or years in the U.S. by state, Census region, phone use (i.e., cellphone only, cellphone mostly, mixed, landline mostly, landline only) and density of the Latino population. The post-stratification weights were trimmed to range from 0.10 to 5.0. After the data were raked to resemble the population distribution for Latino adults, the weighted data were used to determine the benchmark for a Catholic/non-Catholic parameter, which was used to correct for the oversample of non-Catholic Latinos in the study design. Because two versions of the religious affiliation question were used, subsamples were raked separately based on which version of the question respondents received.
Trend Surveys of Hispanics
Most trend analyses in this report are from the 2006 Pew Research Center survey of Hispanics and religion and a subsequent call-back survey of Hispanic Catholics conducted in 2007. The 2006 survey of Hispanics was conducted via landline telephone by International Communications Research (ICR). Interviews were conducted from Aug. 10-Oct. 4, 2006, in both English and Spanish, among a nationally representative sample of 4,016 Hispanic adults. The margin of error for the total sample is plus or minus 2.5 percentage points at the 95% level of confidence. The 2006 survey of Hispanics was followed by a call-back survey of Hispanic Catholics. Survey interviews were completed Jan. 5-29, 2007, with 650 Catholic respondents from the original survey. The margin of error for Hispanic Catholics in the call-back survey is plus or minus 5.7 percentage points at the 95% level of confidence. For more details, see the survey methodology. In this report, the call-back survey is referred to as “2007 Hispanic Catholics.”
The sample design for the 2006 Pew Research survey of Hispanics and religion was stratified to include a disproportionate number of non-Mexican respondents, and included an oversample of non-Catholics by drawing on a re-contact sample of non-Catholic Hispanic respondents from previous ICR studies. Weighting was employed to account for the stratified sample as well as the oversample of non-Catholic Latinos. For more details, see the survey methodology.
The 2006 figures for religious affiliation cited in Chapter 1 of this report vary somewhat from the previous report because the 2006 data were re-weighted using a procedure more comparable to the weighting of the 2013 survey data. In the original 2006 sample, a two-stage weighting design was used to correct for the stratification of the sample and to ensure an accurate representation of the national Hispanic population based on demographic estimates from the Census and Claritas (see the 2006 survey methodology for more information on the original weighting process). The parameter for Catholic/non-Catholic was derived from previous ICR surveys of Hispanics. The new weight, while also first accounting for stratification of sampling and employing post-stratification sample balancing routines to ensure accurate representation based on various demographic parameters, used a religion parameter derived from the post-stratified main sample (excluding the oversample of non-Catholics) to correct for the oversample of non-Catholic Hispanics. This new weight for the 2006 data was only employed for analysis of the religious affiliation profile of Hispanics. Other figures from 2006 are reported using the original weight.
Some figures in this report differ from the 2006 report due to changes in the way respondents were classified. In 2006, the category of “renewalist Protestants” included Jehovah’s Witnesses, Orthodox Christians and Mormons, whereas in this report these groups are not included in the “renewalist Protestant” categories. In addition, subsequent to the publication of the report based on the 2006 survey, it was discovered that due to a programming error in the survey, some respondents were coded as mainline Protestants when they should have been coded as undesignated on their born-again or evangelical status. Therefore, some trend figures for mainline Protestants may be slightly different than previously reported. Also, due to different approaches to rounding, some figures for 2006 may differ by as much as one percentage point between the previous report and the current report.





