This study includes data from four primary sources collected using different methodologies.
Content Analysis
The detailed analysis of the tasks posted on Mechanical Turk consisted of human coding of content that appeared from Dec. 7-11, 2015.
Capture
The most recent 10 pages of HIT groups posted on Mechanical Turk were automatically gathered using a Python scraping tool at three points on each of the five days studied. Each page consists of 20 HIT groups. The times collected were 10 a.m., 3 p.m. and 8 p.m. EST. All the data gathered from the site were publically available.
Because HIT groups are posted so quickly, some of the tasks listed on the 10 pages moved down the list while the scraping tool was running and therefore appeared on more than one of the saved pages. Therefore, the HIT groups collected included a number of duplicates each time. Duplicates were removed after the scraping was complete.
In total, 2,123 different HIT groups were archived during the five-day period.
Human Coding
The unit of measure for the project was the HIT group. No weighting was used in the analysis.
Each HIT group was coded by an experienced researcher for three variables: type of HIT, whether a bonus was mentioned and whether the HIT group explicitly stated that the worker must be at least 18 years old.
Intercoder Testing
To test the validity of the coding scheme, two researchers each coded the same 139 HIT groups that were a subsample of the overall content. The percent of agreement for the three variables were as follows:
HIT Type: 95% Bonus mentioned: 94% Adults only: 99%
Additional Classification
After the coding was completed, researchers classified the HIT groups in two more ways. First, HIT groups that explicitly asked for Turkers who lived in the U.S. were identified.
Second, the requesters for each HIT group were categorized by the type of organization or person. The categories were: business, academic, nonprofit or can’t tell. Because the only information about requesters that is public is their screen name, researchers placed requesters into groups based on any contextual information that was available. This included words that might have appeared in the title or description of the HIT group such as “psychology” or “experiment” (which suggested the requester was likely an academic). Additional Google searches were conducted to try to gain additional information about the requesters when possible. Because some of this information was derived through contextual information, there is the possibility of some error.
All of this categorization is based on the assumption that those who post tasks to MTurk are being truthful when identifying themselves. There is no independent way to confirm whether this is true.
Pew Research Center survey
Data about the demographics and habits of workers come from a nonprobability survey conducted using the Mechanical Turk site. There is no ideal way to get a random sample of workers since their information is private, so the best option is to post HIT groups on the site and get the largest sample of Turkers possible.
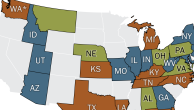
Pew Research Center posted surveys only open to people living in the United States between Feb. 9-25, 2016. Workers were paid variable amounts in order to determine if there were differences in the types of people who respond to different levels of rewards. Workers who were paid 5 cents were only asked questions about their demographics, while those paid 25 cents, 75 cents or $2 were also asked about their use of the site. (The results suggest that there are minor differences in the makeup of workers who responded to the survey with each of the various rewards and will be explored in more detail in a separate report.) In total, 3,370 unique workers responded to the surveys, with 2,884 of those answering the extended set of questions.
Survey estimates presented in this report are not weighted, in part because there are no reliable benchmarks for the population of workers active on Mechanical Turk. No margins of error are reported because this was a nonprobability sample, and we lack data to validate the assumption of approximate unbiasedness.
Data from the U.S. Census
Data regarding the demographics of working adults in the U.S. over the age of 18 came from a Pew Research Center tabulation of the 2015 Current Population Survey Annual Social and Economic Supplement published by the U.S. Census Bureau.
Data from mturk-tracker.com
This report also uses data from the automated data collection site www.mturk-tracker.com, which is run by Dr. Panagiotis G. Ipeirotis of the NYU Stern School of Business. For a full description of the tool written by Ipeirotis, read his paper entitled “Analyzing the Amazon Mechanical Turk Marketplace.”
Pew Research Center collected data from the public mturk-tracker API, which has been gathering and posting data about Mechanical Turk for several years. This report includes data from two of the tracker’s functions.
First, Ipeirotis has been running a regular survey task for Turkers that includes five questions. Each worker who completes the five question survey is paid 5 cents. The Center compiled survey results from 5,918 respondents from Jan. 1, 2016, to Feb. 29, 2016, in order to determine the percent of workers who were located in the U.S.
Second, mturk-tracker has been collecting data on how many HIT groups and HITs have been posted and completed each hour since May 2014. The data are collected by an automated algorithm 24 times each day. Pew Research Center compiled and analyzed the raw data provided by mturk-tracker’s API. (Note: Two days did not have any values in the dataset, Feb. 19 and 20, 2015.)