
Factor Analysis
Factor analysis is also known as latent variable analysis. It is a statistical technique aimed at answering the question: What are the underlying and unobserved factors that may explain – and, importantly, summarize – complex phenomenon? A classic use of factor analysis is to determine where people fall on the political spectrum. One cannot observe directly whether someone is liberal or conservative, but through a series of questions about how people behave and what their attitudes are, factor analysis permits a statistician to use observed variables (does a person support affirmative action, vote for Democrats, favor funding for social programs?) to explain an unobserved variables (she’s a liberal or conservative).
Factor analysis is useful for the Pew Internet Project’s March-May 2002 survey. There are a wide range of questions about who people are and what they do (online and offline), but we have few preconceived notions, and little theory, about how individuals’ characteristics may influence the decision to obtain Internet access.
A number of factors grouped together in statistically meaningful and intuitive ways. The following list consists of the Project’s labels for the grouping and the variables from the survey that define the labels:
- Personal Time is made up of those who said they were satisfied with the time they spend with friends, family, on their hobbies, or for relaxation.
- Social Network consists of respondents who say they often (i.e., “every day” or “a few times a week”) visit with family or friends, dine with family or friends, or call family or friends just to talk.
- Social Capital captures traditional measures of social capital such as whether a person belongs to a community group or whether a person belongs to a social club.
- Other Groups: although only a small share of our respondents (about 6%) said they belong to “other” groups, it was a distinct category. Those who said they belong to “other” groups classified themselves as group members, but not in any of the groups on which they were prompted, namely a community group, social club, youth group, a church group, or local sports league.
- Church Goers: those who belong to and attend church often.
- Social Contentment is made up of people who think most people are fair, can be trusted, and who have people to turn to for support. Whites also group in this factor.
- Internet/Computer users: those people with online access and who identify themselves as computer users.
- Extrovert captures respondents who describe themselves as outgoing, talkative, and assertive.
- Media Use: captures respondents who, on a typical day, watch any TV, watch TV news, or read a newspaper.
Regression Analysis
The next step is a regression model that seeks to explain what causes people to adopt the Internet. The groupings that the factor analysis yielded on social and personal traits were included, as well as those relating to media use and technology traits. Demographic variables round out the types of variables included in each specification.
Three models are reported in order to see how robust estimates are to the inclusion or exclusion of different variables. Model I includes all variables except “social contentment”; instead the dichotomous variables for trust, support, and satisfaction with the country’s direction are included. Model II substitutes the “social contentment” variable for those variables. The variable for “whites” is excluded here, as it groups with “social contentment”. Finally, Model III excludes the variables on personal technology use (i.e., cell phones and personal digital assistants). As discussed more fully below, the causal relationship between these variables and Internet use may run both ways, making it sensible from an econometric perspective to exclude them.
Interpreting Results
In interpreting the following table, an odds ratio greater than one means that a user having the behavioral characteristic associated with that variable has a greater likelihood of having Internet access. Variables with asterisks have statistical significance; those without asterisks lack explanatory power. The odds ratio also allows us to compare the magnitude of the independent effects. For example, being a student is the strongest predictor of whether one goes online, followed by being a college graduate.
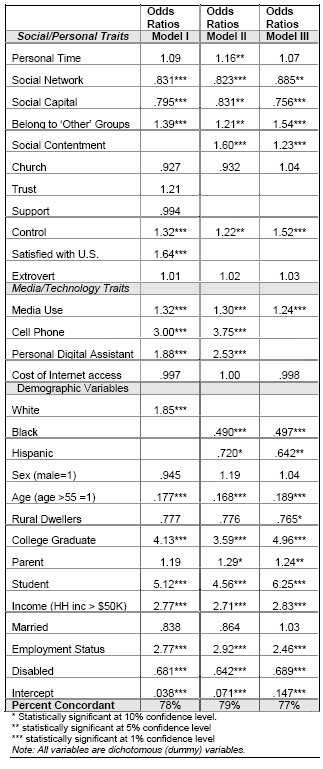
Finally, the “percent concordant” is a measure of how successfully the models predicts whether respondent go online. We know from the data which people go online; running the data through the models predicts correctly who goes online from between 77% and 79% of the time. In other words, that is nearly 30% better than flipping a coin. By the standards of this kind of regression model (a logistic regression), this is quite good.
Result: Discussion
In many ways, demography is destiny when it comes to predicting who will go online. Having a college degree, being a student, being white, being employed, and having a comfortable income each independently predict Internet use. Notably, gender is not a significant factor. As for race, being white is a strong predictor of whether one is online (Model I), controlling for all the other demographic variables in the model. When the model was run with blacks and Hispanics as the race variable (Model III), being black or Hispanic was a negative predictor of online access. Since being white groups with social contentment, the fact that social contentment is positive and significant in Model III, along with the presence of other racial categories in that model, is strong evidence that being white is a strong influence to going online. In sum, race matters; holding all other things constant, blacks and Hispanics are less likely to go online than whites.
The other variables yield a couple of insights. Those whose worlds seem to be close around them are less likely to go online. People who belong to a community group or social club (i.e., those with traditional measures of social capital) are less likely to be online.11 Those with an active and immediate social network (i.e., those who frequently visit, talk, or dine with friends and family) are also less likely to go online. In slight contrast, those who are satisfied with the amount of time they can devote to family, friends, hobbies, and relaxation are more likely to be online. However, the size of this variable’s predictive power is small and it is significant in only one model. In sum, it seems that the physical proximity of people and groups that matter to these people leaves little room (or need) for the Internet.
People who exhibit a positive and outward orientation toward the world are more likely to be Internet users. Those who feel they have a lot of control over their lives, and who are also satisfied with the direction in which the United States is heading are more likely to go online than those who do not feel that way. The variable “social contentment” reflects a grouping of people who think other people are fair, can be trusted, have others to turn to for support, and are white. That variable is significant in two models, and remains significant when the “white” variable is included. Since econometrically one would expect including both “social contentment” (which partially captures race) and the race variable for white Americans to lessen the significance of each, this suggests that race and notions of social contentment are strongly related to Internet adoption. Finally, media use – those who watch TV news, read the newspaper, and regularly watch TV and arguably an indicator of an outward orientation – is also a positive predictor of Internet use.
Of course, it is possible to have both an outward orientation toward the world, and a “close in” social universe (as measured by social capital and nearby social networks). According to the model, if you are such a person, the odds are in favor of you being online. In other words, a person’s outward orientation would outweigh a “close in” social universe and mean that a person possessing both characteristics is more likely than not to be online.
As for cost, the monthly cost of Internet access does not appear to have much to do with the decision to be online; in no specification was the cost a significant predictor of whether a person goes online. Finally and unsurprisingly, having technology is associated with Internet use. Those who have cell phones or personal digital assistants are likely to use the Internet.
Including personal technologies (cell phone and PDAs) in the models raise the issue of causality. Having a cell phone may not cause one to obtain Internet access, but rather having several personal technologies is part of the same related process of being wired (e.g., with the Internet, a personal computer, a cell phone, etc.). Econometrically, this would bias the estimates in the models. Therefore, Model III excludes those variables. The predictive power of the model declines only slightly, and the signs, significance, and magnitude of the remaining parameter estimates remain the about same, with the “college graduate” and “student” variables picking up additional predictive power.
The three models, then, portray a consistent picture; demographic characteristics (education, income, race, and others) are the strongest predictors of whether people use the Internet. People exhibiting a strong degree of social contentment—whether measured by the “social contentment” variable as defined above or by saying they have control of their lives, trust in others, and people to turn to for help—are more likely to be online. Those who seem to have their social life very much nearby—those who belong to a community group or social club and those who often visit with, talk to, or dine with family and friends—are less likely to be online.
Appendix A was written by Dr. John Horrigan, the senior research specialist at the Pew Internet & American Life Project.





