
To analyze how legislators in three countries outside the United States used Twitter to discuss the U.S. elections and presidential candidates in the run-up to the election, researchers obtained 167,464 public tweets from each of the 1,289 members of national legislatures in the United Kingdom, Australia and Canada who tweeted between Aug. 28 and Sept. 30, 2020. Researchers used the public Twitter Application Programming Interface (API) to collect the tweets. Of 1,289 legislators who have a Twitter account and posted at least once in the period directly after the end of the Republican National Convention until the end of September, 272 legislators, or 21%, tweeted or retweeted content related to presidential candidates. And 42% tweeted or retweeted content related to the U.S. more broadly, with 10% specifically relating to the upcoming November elections.
Researchers also obtained a second batch of 42,398 public tweets from 1,228 members of these national legislatures who tweeted in the week of Nov. 7 – when Joe Biden was announced the winner of the election – to Nov. 14. Of the 1,228 legislators who have a Twitter account and posted at least once in the week after Biden won the election, 698 legislators, or 57%, tweeted or retweeted content related to the presidential candidates or their running mates.
Identifying tweets about presidential candidates and their running mates
To identify tweets about presidential candidates for the Republican and Democratic parties – Donald Trump and Joe Biden, respectively – researchers used a case-insensitive regular expression, or a pattern of keywords, that consists of the terms: “Donald Trump,” “Joe Biden,” “Trump,” “Biden,” “realdonaldtrump,” “joebiden,” etc. This pattern identified 821 tweets mentioning Trump and 355 tweets mentioning Biden explicitly by name in the preelection set of tweets, and 813 tweets mentioning Trump and 2,170 tweets mentioning Biden in the post-election set. Researchers also used negative lookahead to exclude mentions of people who share the last name of the candidates, such as Ivanka Trump or Hunter Biden. After accounting for false positives, researchers analyzed 814 tweets about Trump and 352 tweets about Biden in the final preelection dataset. In the post-election dataset, we analyzed 803 tweets about Trump and 2,122 tweets about Biden. Researchers did not search for any third-party candidates.
Researchers also searched for tweets about the presidential candidates’ running mates, Sen. Kamala Harris and Vice President Mike Pence. In the preelection dataset, the only tweet that mentioned Pence also referenced Donald Trump and was not analyzed separately. Eleven tweets mentioned Kamala Harris but not Joe Biden. Because of this low volume for tweets mentioning Pence and Harris, the preelection set of tweets focuses only on mentions of the presidential candidates. In the post-election dataset, we again saw few mentions of Pence independent from mentions of Trump. Tweets mentioning Harris without Biden, such as mentions of her historic accession to the vice presidency, are included in the post-election analysis. These account for 370 tweets, or 14%, of post-election tweets that mention Biden or Harris.
To evaluate the performance of the regular expression, researchers took a random sample of 100 tweets about Trump and 100 tweets about Biden created between Aug. 28 and Sept. 30, 2020, and an additional two groups of 100 flagged as not mentioning Trump or Biden from the same time period. A researcher examined these sets and independently determined whether they mentioned the presidential candidates in order to compare human decisions with the results from the regular expression. Overall, the human decisions agreed with the keyword method 98% of the time. Cohen’s Kappa – a statistic that examines agreement while adjusting for chance agreement – was 0.96 on average between Trump and Biden mentions for the same comparison. Another researcher also classified the set of 200 tweets for each candidate independently to ensure their decisions were comparable. Cohen’s Kappa for coder-to-code comparisons was 0.98 for mentions of Biden and 1 (perfect agreement) for Trump.
Coding of legislators’ pre-election tweets
Sentiment coding for tweets about presidential candidates before the election
Using the validated tweets about presidential candidates, researchers hand-coded the sentiment of each tweet into one of three categories: positive, neutral or negative.
Tweets with a positive mention:
- Include any tweets in which the writer explicitly says the above parties are doing a good job, showing leadership, etc.
- Also include general expressions of thanks or gratitude or wishing them luck in the upcoming election.
Tweets with a negative mention:
- Include any tweets in which the writer explicitly says the above parties are doing a bad job, failing at key tasks or at their jobs more broadly or letting Americans down.
- Also include general expressions of shame or embarrassment, or hoping that they will lose in the upcoming election.
- Or refer to the candidates in disparaging terms, such as the phrases “Sleepy Joe” or calling something negative “Trumpian.”
Tweets that are neutral:
- Include any tweets that do not express feelings toward any candidates on either party’s presidential ticket or are strictly descriptive in nature regarding the candidate or related polling and news. For example, “Looking forward to joining the panel on the eve of the first Biden-Trump presidential debate. https://t.co/LkQo18EgyE” is considered a neutral tweet toward both candidates.
Researchers coded tweets about Trump and tweets about Biden separately in order to accurately classify tweets that mention both candidates. In the majority of cases, researchers were able to determine a tweet’s sentiment based solely from the text of the tweet. In some cases, such as links to political cartoons, researchers followed links or images for additional context before making a decision. Through this process, researchers removed 10 false positives. It is important to note that this method may fail to correctly classify tweets that use irony or sarcasm to convey feelings or ideas about the candidates.
Identifying subtopics in the preelection sentiment coding
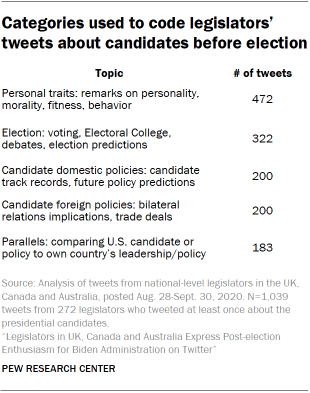
In addition to classifying the sentiment of these tweets, researchers also coded them into subtopics. Researchers manually examined this sample of tweets and retweets to assess which topics were prevalent when discussing the candidates. Based on manual examination, researchers generated a list of coding categories and separately coded the tweets into agreed-upon categories. The tweets were analyzed in two batches – those about Biden and those about Trump – and coded as being about that candidate specifically using the same criteria. Tweets that mentioned both Trump and Biden were coded independently in each set.
Five researchers then separately coded 200 tweets and achieved high levels of intercoder reliability on the subset that they all reviewed (average Krippendorf’s alpha between the Biden and Trump set ranging from 0.76 to 0.87 for each topic) before each coding part of the remaining sample.
Researchers coded the tweets primarily by reading the text of each tweet. In some cases, when a tweet contained attachments such as links or images, they were considered for additional context before making a decision. It is important to note that this method may fail to correctly classify tweets that use irony or sarcasm to convey feelings or ideas about the U.S. In other words, this analysis captures only the specific subset of the larger conversation on Twitter among legislators that involves overt or explicit discussion of, or engagement with, these topics.
Identifying tweets about the United States
To identify tweets about the United States broadly, researchers used a case-insensitive regular expression that consists of the terms: “United States,” “unitedstates,” “US,” “USA,” “U.S.,” etc. This pattern identified 1,905 tweets as mentioning the U.S. explicitly by name. Researchers also used negative lookahead to exclude mentions of places contain the word America but do not refer to the country, e.g., Latin America. After accounting for false positives, researchers analyzed 1,794 tweets about the United States in the final dataset.
To evaluate the performance of the regular expression, researchers took a random sample of 400 tweets created between Aug. 28 and Sept. 30, 2020. Two researchers examined this set to determine whether they mentioned the U.S. by name in order to compare human decisions with the decisions from the regular expression. Overall, the human decisions agreed with the keyword method 96% of the time. Cohen’s Kappa was 0.90 for the same comparison. Another researcher also classified the set of 400 tweets independently to ensure their decisions were comparable. Cohen’s Kappa for coder-to-code comparisons was 0.96.
Topic coding for tweets related to the U.S.

Researchers limited their analysis of tweets that explicitly mentioned the U.S. to those created from Aug. 28 through Sept. 30, 2020. Researchers manually examined this sample of tweets and retweets to assess which topics were prevalent when discussing these topics. Based on this manual examination, researchers generated a list of coding categories and separately coded the tweets into agreed-upon categories.
Four researchers then separately coded 100 tweets and achieved high levels of intercoder reliability on the subset that they all reviewed (Krippendorf’s alpha ranging from 0.75 to 0.96 for each topic) before each coding part of the remaining sample. For 111 tweets, researchers found false positives or ambiguous content and dropped these from the analysis. For example, the “US” keyword falsely tagged tweets containing currency symbols (e.g., “US$”) that are not actually about the U.S.
Researchers coded the tweets mainly through reading the text of each tweet. In some cases, when a tweet’s topic could not be discerned from the text alone, researchers used links or images in the tweet for additional context before making a decision. It is important to note that this method may fail to correctly classify tweets that use irony or sarcasm to convey feelings or ideas about the U.S. In other words, this analysis captures only the specific subset of the larger conversation on Twitter among legislators that involves overt or explicit discussion of, or engagement with, these topics.
For more information on the Center’s global legislators database research, see “For Global Legislators on Twitter, an Engaged Minority Creates Outsize Share of Content”and its methodology page here.
Coding of legislators’ post-election tweets
Sentiment coding for tweets about presidential candidates after the election
Using the validated tweets about presidential candidates and their running mates sent from Nov. 7 to 14, researchers hand-coded the sentiment of each tweet into one of three categories: positive, neutral or negative.
Tweets with a positive mention:
- Include any tweets in which the writer explicitly says the above parties are doing a good job, showing leadership, etc.
- Also include general expressions of thanks, gratitude or satisfaction with respect to the election outcome.
Tweets with a negative mention:
- Include any tweets in which the writer explicitly says the above parties are doing a bad job, failing at key tasks or at their jobs more broadly or letting Americans down.
- Also include general expressions of shame, embarrassment or dissatisfaction with the results of the election. Expressions of satisfaction or gratitude toward certain candidate’s defeat in the election also belong in this category.
- Or refer to the candidates in disparaging terms, such as the phrases “Sleepy Joe” or calling something negative “Trumpian.”
Tweets that are neutral:
- Include any tweets that do not express feelings toward any candidate on either party’s presidential ticket or are strictly descriptive in nature regarding the candidate, election or related polling and news.
Researchers coded tweets about Trump and tweets about Biden separately in order to accurately classify tweets that mention both candidates. In the majority of cases, researchers were able to determine a tweet’s sentiment based solely on the text of the tweet. In some cases, such as links to political cartoons, researchers followed links or images for additional context before making a decision. Through this process, researchers removed 10 false positives. It is important to note that this method may fail to correctly classify tweets that use irony or sarcasm to convey feelings or ideas about the candidates.
Identifying subtopics in the post-election sentiment coding
In addition to classifying the sentiment of these tweets, researchers also coded them into subtopics. Researchers manually examined this sample of tweets and retweets to assess which topics were prevalent when discussing the candidates. Based on manual examination, researchers generated a list of coding categories and separately coded the tweets into agreed-upon categories. The tweets were analyzed in two batches – those about Biden/Harris and those about Trump/Pence – and coded about that candidate pair specifically using the same criteria. Tweets that mentioned both Trump and Biden were coded independently in each set.

Five researchers then separately coded 200 tweets and achieved high levels of intercoder reliability on the subset that they all reviewed (average Krippendorf’s alpha between the Biden and Trump set ranging from 0.73 to 0.84 for each topic) before each coding part of the remaining sample.
Researchers coded the tweets primarily by reading the text of each tweet. In some cases, when a tweet contained attachments such as links or images, they were considered for additional context before making a decision. It is important to note that this method may fail to correctly classify tweets that use irony or sarcasm to convey feelings or ideas about the U.S. In other words, this analysis captures only the specific subset of the larger conversation on Twitter among legislators that involves overt or explicit discussion of, or engagement with, these topics.





