
The American Trends Panel survey methodology
Overview
The American Trends Panel (ATP), created by Pew Research Center, is a nationally representative panel of randomly selected U.S. adults. Panelists participate via self-administered web surveys. Panelists who do not have internet access at home are provided with a tablet and wireless internet connection. Interviews are conducted in both English and Spanish. The panel is being managed by Ipsos.
Data in this report is drawn from the panel wave conducted from Dec. 12 to Dec. 18, 2022. A total of 11,004 panelists responded out of 12,448 who were sampled, for a response rate of 88%. The cumulative response rate accounting for nonresponse to the recruitment surveys and attrition is 4%. The break-off rate among panelists who logged on to the survey and completed at least one item is 2%. The margin of sampling error for the full sample of 11,004 respondents is plus or minus 1.4 percentage points.
Panel recruitment
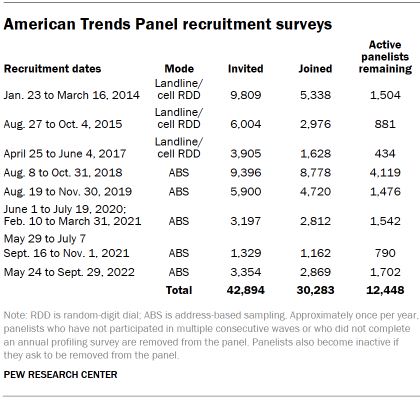
The ATP was created in 2014, with the first cohort of panelists invited to join the panel at the end of a large, national, landline and cellphone random-digit-dial survey that was conducted in both English and Spanish. Two additional recruitments were conducted using the same method in 2015 and 2017, respectively. Across these three surveys, a total of 19,718 adults were invited to join the ATP, of whom 9,942 (50%) agreed to participate.
In August 2018, the ATP switched from telephone to address-based recruitment. Invitations were sent to a stratified, random sample of households selected from the U.S. Postal Service’s Delivery Sequence File. Sampled households receive mailings asking a randomly selected adult to complete a survey online. A question at the end of the survey asks if the respondent is willing to join the ATP. In 2020 and 2021 another stage was added to the recruitment. Households that did not respond to the online survey were sent a paper version of the questionnaire, $5 and a postage-paid return envelope. A subset of the adults who returned the paper version of the survey were invited to join the ATP. This subset of adults received a follow-up mailing with a $10 pre-incentive and invitation to join the ATP.
Across the five address-based recruitments, a total of 23,176 adults were invited to join the ATP, of whom 20,341 agreed to join the panel and completed an initial profile survey. In each household, one adult was selected and asked to go online to complete a survey, at the end of which they were invited to join the panel. Of the 30,283 individuals who have ever joined the ATP, 12,448 remained active panelists and continued to receive survey invitations at the time this survey was conducted.
The U.S. Postal Service’s Delivery Sequence File has been estimated to cover as much as 98% of the population, although some studies suggest that the coverage could be in the low 90% range.1 The American Trends Panel never uses breakout routers or chains that direct respondents to additional surveys.
Sample design
The overall target population for this survey was non-institutionalized persons ages 18 and older, living in the U.S., including Alaska and Hawaii. All active panel members were invited to participate in this wave.
Questionnaire development and testing
The questionnaire was developed by Pew Research Center in consultation with Ipsos. The web program was rigorously tested on both PC and mobile devices by the Ipsos project management team and Pew Research Center researchers. The Ipsos project management team also populated test data that was analyzed in SPSS to ensure the logic and randomizations were working as intended before launching the survey.
Incentives
All respondents were offered a post-paid incentive for their participation. Respondents could choose to receive the post-paid incentive in the form of a check or a gift code to Amazon.com or could choose to decline the incentive. Incentive amounts ranged from $5 to $20 depending on whether the respondent belongs to a part of the population that is harder or easier to reach. Differential incentive amounts were designed to increase panel survey participation among groups that traditionally have low survey response propensities.
Data collection protocol
The data collection field period for this survey was Dec. 12 to Dec. 18, 2022. This survey included a postcard experiment in which postcard notifications were mailed to half of ATP non-tablet household panelists with a known residential address on Dec. 12, 2022. The other half of ATP panelists did not receive any postcard mailings. The survey-level response rate was 89% among those mailed the postcard and 88% among those who were not mailed the postcard.
Invitations were sent out in two separate launches: Soft Launch and Full Launch. Sixty panelists were included in the soft launch, which began with an initial invitation sent on Dec. 12, 2022. The ATP panelists chosen for the initial soft launch were known responders who had completed previous ATP surveys within one day of receiving their invitation. All remaining English- and Spanish-speaking panelists were included in the full launch and were sent an invitation on Dec. 13, 2022.
All panelists with an email address received an email invitation and up to two email reminders if they did not respond to the survey. All ATP panelists that consented to SMS messages received an SMS invitation and up to two SMS reminders.

Data quality checks
To ensure high-quality data, the Center’s researchers performed data quality checks to identify any respondents showing clear patterns of satisficing. This includes checking for very high rates of leaving questions blank, as well as always selecting the first or last answer presented. As a result of this checking, eight ATP respondents were removed from the survey dataset prior to weighting and analysis.
Weighting
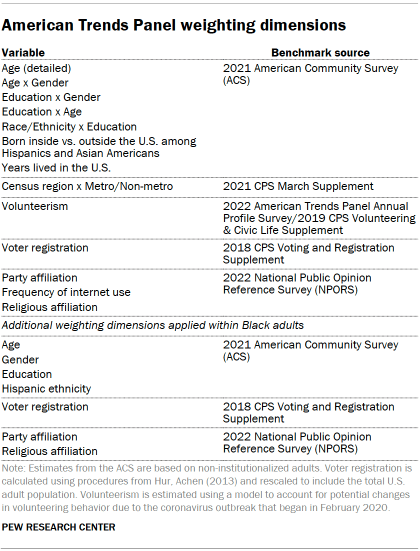
The ATP data is weighted in a multistep process that accounts for multiple stages of sampling and nonresponse that occur at different points in the survey process. First, each panelist begins with a base weight that reflects their probability of selection for their initial recruitment survey. These weights are then rescaled and adjusted to account for changes in the design of ATP recruitment surveys from year to year. Finally, the weights are calibrated to align with the population benchmarks in the accompanying table to correct for nonresponse to recruitment surveys and panel attrition. If only a subsample of panelists was invited to participate in the wave, this weight is adjusted to account for any differential probabilities of selection.
Among the panelists who completed the survey, this weight is then calibrated again to align with the population benchmarks identified in the accompanying table and trimmed at the 1st and 99th percentiles to reduce the loss in precision stemming from variance in the weights. Sampling errors and tests of statistical significance take into account the effect of weighting.
The following table shows the unweighted sample sizes and the error attributable to sampling that would be expected at the 95% level of confidence for different groups in the survey.
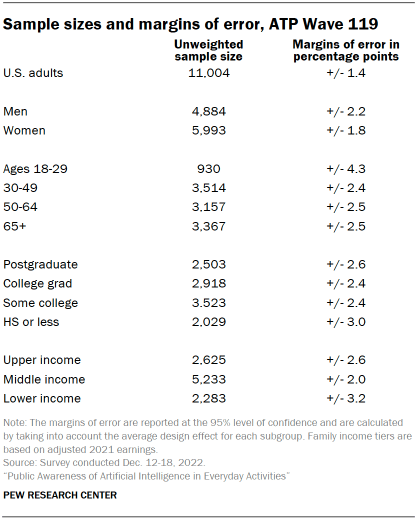
Sample sizes and sampling errors for other subgroups are available upon request. In addition to sampling error, one should bear in mind that question wording and practical difficulties in conducting surveys can introduce error or bias into the findings of opinion polls.
Dispositions and response rates


Adjusting income and defining income tiers
To create upper-, middle- and lower-income tiers, respondents’ 2021 family incomes were adjusted for differences in purchasing power by geographic region and household size. “Middle-income” adults live in families with annual incomes that are two-thirds to double the median family income in the panel (after incomes have been adjusted for the local cost of living and household size). The middle-income range for the American Trends Panel is about $43,800 to $131,500 annually for an average family of three. Lower-income families have incomes less than roughly $43,800, and upper-income families have incomes greater than roughly $131,500 (all figures expressed in 2021 dollars).
Based on these adjustments, 28% of respondents are lower income, 46% are middle income and 18% fall into the upper-income tier. An additional 6% either didn’t offer a response to the income question or the household size question.
For more information about how the income tiers were determined, please see here.
A note about the Asian adult sample
This survey includes a total sample size of 371 Asian adults. The sample primarily includes English-speaking Asian adults and, therefore, may not be representative of the overall Asian adult population. Despite this limitation, it is important to report the views of Asian adults on the topics in this study. As always, Asian adults’ responses are incorporated into the general population figures throughout this report.
Measurement properties of the awareness of artificial intelligence in daily life scale
Pew Research Center’s survey on awareness of artificial intelligence in daily life asked respondents to identify AI applications in email, online shopping, customer service and other areas they might encounter. The scale included six different questions to measure how aware people are of AI applications. These questions represent some common ways people could use AI in their lives but are not designed to be an exhaustive list of all the ways people could encounter AI.
The following criteria are used to evaluate how well the six items scale as an index of awareness of AI in daily life: 1) the degree to which responses are internally consistent 2) the degree to which the questions reflect a single underlying latent dimension and 3) the degree to which the scale discriminates between people with high and low awareness of AI in daily life.
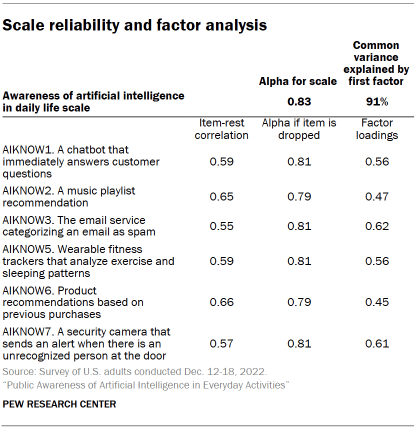
The internal reliability of the scale as measured by Cronbach’s alpha is 0.83. Cronbach’s alpha does not increase if any of the items is dropped.
An exploratory factor analysis finds that the first common factor explains 91% of the shared variance in the items. The factor loadings show that each of the six items is at least moderately correlated with the first common factor. This suggests that the set of items is the result of a single underlying dimension.
Note that all the awareness of AI in daily life items are coded as binary variables (either correct or incorrect). Both Cronbach’s alpha and factor analysis are based on a Pearson’s correlation matrix. Pearson’s correlations with binary variables are restricted to a limited range, underestimating the association between two variables. We do not anticipate the use of a Pearson’s correlation matrix will affect the unidimensional factor solution for the scale.
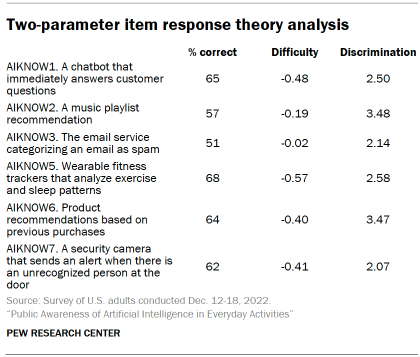
We conducted item response modeling for the scale to evaluate how well it discriminates between people at different levels of awareness. The analysis fits a two-parameter logistic model, allowing discrimination and difficulty to vary across items. Discrimination shows the ability of the question to distinguish between those with higher and lower awareness of AI in daily life. Difficulty shows how easy or hard each question is for the average respondent.
All the items have acceptable discrimination estimates. The two items with the highest discrimination were knowing that a music playlist recommendation uses AI and product recommendations based on previous purchases when shopping online uses AI.
The difficulty parameter estimates are negative for all six items. The scale did not include a more difficult item with a positive difficult value. Because of this, the items did not have much variation in difficulty.
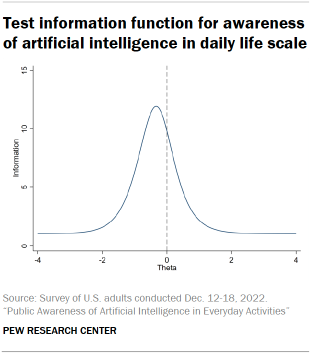
The test information function shows the amount of information the scale provides about people with different levels of awareness of artificial intelligence in daily life. The test information function approximates a normal curve and is centered below zero at about -0.35. This indicates that the scale provides the most information about those with slightly below-average awareness. The scale provides comparatively less information about those with high awareness, especially very high awareness.
© Pew Research Center 2023





