To analyze the content of congressional outreach, researchers gathered a comprehensive set of Facebook posts and press releases issued by offices of members of the U.S. Senate and House of Representatives between Jan. 1, 2015, and April 30, 2016. Facebook posts were obtained from the legislators’ official pages (via API) and press releases were collected by combining two sources: official websites and an online database (LexisNexis). The research team analyzed the resulting corpus of posts and releases using a combination of traditional content analysis and machine-learning techniques.
Facebook posts from official accounts
Collecting Facebook page posts via API
In order to identify official Facebook accounts associated with members of the 114th Congress, researchers first recruited workers from Mechanical Turk, an online labor market. Researchers provided a list of U.S. senators and representatives in the 114th Congress to workers, who then searched for their Facebook accounts.19
The assignments were issued and completed on Feb. 1, 2016. A total of 59 Mechanical Turk workers assisted in the account identification process.
Researchers manually verified that accounts were associated with the correct Congress member for cases in which workers reported only a single Facebook account, or reported a single account for more than one politician. During this process, 17 accounts were found to be unofficial “fan pages” or parody accounts, and were removed from the list. Researchers also cross-referenced and supplemented account information with data from the open-source @unitedstates project.
Most members of Congress maintain multiple social media accounts, one of which is often used as the member’s “official’’ account. These official accounts are used to communicate information as part of the member’s representational or legislative capacity, and House members may use official staff resources appropriated by the U.S. House or Senate. Personal and campaign accounts may not draw on these government resources under official House and Senate guidelines.20
Researchers classified Facebook accounts as official or unofficial based on the links to and from their official “.gov’’ pages. Accounts were classified as official if they met any of the following criteria: if the politician’s official house.gov or senate.gov homepage linked to the Facebook account, if the Facebook account’s profile contained a link to a house.gov or senate.gov homepage, or if it referenced or was referenced by a Twitter profile that met either of the two previous homepage linking conditions. Rules prohibit linking between official (.gov) and campaign websites or accounts, as well as linking from an official site or account to a personal site or account. But linking from a personal site or account to an official website or account is allowed. Hence, it is possible that some Facebook accounts classified as official were in fact personal accounts. However, researchers examined accounts manually and deemed this highly unlikely based on their content.
Accounts not classified as official according to this scheme were deemed unofficial accounts. Five Congress members had two pages that met these conditions. In these cases, posts from both pages were included in the analysis. Additionally, the 29 members that were initially determined to have no official accounts using this method were reviewed manually. During this process, six of them were identified as being official despite failing the above criteria, and were accordingly corrected.
After generating a list of official and unofficial congressional Facebook accounts, researchers used Facebook’s Open Graph Pages API to access all publicly available posts for each member’s page(s). These included plain-text status updates as well as updates with shared links, photos, and videos, and event announcements and invitations. The text from each post was saved as a distinct document, including the URL, title, preview excerpt and/or caption associated with any shared content (such as a link or video), as well as any comments made by the member. All posts used in this report were re-synced and updated via the API between June 14 and June 16, 2016, in order to ensure that the posts were as up-to-date as possible, and to ensure that likes and comments for posts created in late April were not artificially constrained by our sample timeframe. The share counts for each post were synced between Nov. 3 and Nov. 5, 2016.The resulting dataset contains 162,609 Facebook posts from 978 different accounts belonging to 541 different members of Congress.21 A total of 523 of these accounts are official and belong to 518 different members, while 455 are unofficial, belonging to 449 different members. According to the official-unofficial classification strategy used here, 518 members of Congress (96%) who use Facebook for outreach had an official account, and 426 (79%) had at least one unofficial account in addition to their official ones. Furthermore, 92 members (17%) had only official accounts, and 23 (4%) had unofficial campaign or personal accounts but no official accounts. Overall, 109,411 (67.3%) of the 162,609 posts were from official accounts.
The vast majority of the posts in the dataset are link shares (130,850, or 80.5%) or plain-text status updates (29,479, or 18.1%), with the remaining 1.4% comprised of miscellaneous other forms of posts. Photo and video posts were excluded from this analysis. Researchers also did not include any content from shared webpage links except for the caption and preview made available on Facebook. The findings presented in this report exclude posts by nonvoting representatives as well as members with fewer than 10 official Facebook posts, bringing the final number of Facebook posts to 108,235 posts from 509 members.
Press releases
Researchers obtained press releases issued by members of Congress in two ways: by downloading documents directly from the members’ official websites, and by searching for and retrieving documents from LexisNexis.
Researchers collected a total of 96,064 press releases for 542 different members of Congress. All analyses here exclude members with fewer than 10 published press releases, bringing the sample to 538 legislators. We further excluded nonvoting members, bringing the total to 532 members and 94,521 individual releases.
Collecting press releases from official websites
To collect press releases from members’ official websites, a list of homepage links was collected from the house.gov and senate.gov websites. In-house researchers and contracted assistants from Upwork manually examined each member’s website, identified the “News Release” or “Press Release” section for each, and assessed the source code of the website to determine how the releases were organized, and where various attributes of each release such as the title, text and publication date could be found on each page. This information was then formalized into a set of Python scripts that used custom logic and parameters (i.e., XPath queries) to identify, parse, and store data for each representative’s website.
Collecting press releases from LexisNexis
The press releases collected from members’ official websites were supplemented with documents from LexisNexis. Using the LexisNexis Web Services Kit API, five different aggregate news collections were included in the search: US Fed News, Targeted News Service, US Official News, CQ Congressional Press Releases, and Government Publications and Documents. This query relied on a Boolean search designed to capture combinations of indicators of press releases.22 These parameters were the result of iterative testing that minimized false positives.
Name Matching
Politicians were identified using a set of four sections of text, combined with three regular expressions into a set of seven different search conditions. To compile the list of text sections to search for each document, the algorithm first scanned the raw document XML for metadata, which occasionally contained the names of members of Congress (1). This was then added to a list along with the article’s title (2), the first 250 characters of the document’s text (3), and the last 150 characters of the text (4). Three regular expressions were developed to search through these sections, available in Appendix A, section A2.
The four search sections and three regular expressions were then combined into search criteria representing patterns where politicians’ names had been reliably identified during a process of manual review. In that process, none of the following combinations produced a false positive: 1a, 1b, 2a, 2b, 3a, 3b, 4c. If any names were extracted using these seven searches, the names were then used to search a list of Congress members for the document’s year of publication.
Researchers used a Python script to search for and download the raw text of documents published between January 2015 and April 2016. Researchers then used regular expressions to extract members’ first and last names from key sections in each document that contained authorship information (see sidebar). Press releases issued by multiple members were attributed to all members listed.
Researchers used a fuzzy matching algorithm23 to check each identified name against a list of members of Congress during the document’s year of publication. Nine possible combinations of members’ first, middle and last names, nicknames and suffixes were tested on each identified name, and a similarity ratio was computed for every pairing. If the top-matching name was found to have a similarity ratio higher than 70%, the corresponding member was then associated with the document and the press release was saved to the database.24
To correct mismatches that may have occurred between politicians with similar names, random samples of 20 LexisNexis press releases were extracted for each politician and reviewed to confirm that the associated legislator was among the authoring politicians mentioned in the text of the release. A total of 40 sets of politicians were identified between whom press releases had been misattributed – many of which shared a common last name – and custom scripts were written and applied to correct the errors. Misattribution patterns were also created to filter out releases by state senators, congressional committees and state political parties.
While largely automated, this process was closely monitored and deletions were manually verified for every single member of Congress whenever more than 25% of their LexisNexis releases failed to meet the criteria.
Cleaning and deduplication
Since this dataset was derived from multiple sources, there was a high probability of duplicate releases. Deduplication required the removal of boilerplate content, which often existed in one source but not another, as well as the correction of errant dates.
Removing boilerplate content
The raw text of the press releases often contained boilerplate text, defined as sentences that did not contain any information related to the substantive topic(s) of the press release. For example, the websites of members of Congress often append contact information at the end of each release, and LexisNexis articles often contain publisher and copyright information at the top of each release. In order to accurately represent the substantive content of these documents and make comparisons between them, this extra information had to be removed.
[S]
Every press release from LexisNexis was scanned for these patterns, and if any of these markers were found, boilerplate text was removed. During this process, unusual cases – where the text to be removed consisted of 250 or more characters or constituted greater than 40% of the entire document’s length – were reviewed manually to ensure that deviations from the expected boilerplate patterns did not result in erroneous text removal. A few such cases were encountered, all of which were short press releases that fit the expected pattern. Similarly, while website-based press release boilerplate was less consistent, one footer pattern that indicated the end of an official release was frequent enough across multiple websites to remove in the same manner as those above (r`###’ ).
However, most instances of bad content were too inconsistent and diverse to be removed with a small set of fixed rules.
To implement a more flexible approach, researchers developed a parsing algorithm to split press release content into sentences, based on the NLTK Punkt English tokenizer. The tokenizer was expanded to use the following regular expressions to mark the beginning of sentences, which helped identify boilerplate sentences.25
Next, a machine-learning approach was employed to classify sentences as boilerplate or not. First, a sample of 4,516 documents across 634 different members of Congress (and the sentences therein) was extracted for manual review and verification.26
Examples of boilerplate sentences include:
- Read more here: http://www.newsobserver.com/2014/02/04/3590534/rep-mcintyre-of-nc-laments-too.html
- District Office Washington Office District Office 1717 Langhorne Newtown Rd.
- Your browser does not support iframes.
- Welcome to the on-line office for Congressman Donald Payne, Jr.
- “>’ ); document.write( addy71707 ); document.write( ’</a>’ ); //–>kdcr@dordt.edu’ );//–>
- You can reach Rep. Beyer on the web at www.beyer.house.gov , on Facebook at facebook.com/RepDonBeyer and on Twitter @RepDonBeyer.
- Washington, DC Office 2417 Rayburn HOB Washington, DC 20515 Phone: (202) 225-2331 Fax: (202) 225-6475 Hours: M-F 9AM-5PM EST
- He represents California’s 29th Congressional District, which includes the communities of Alhambra, Altadena, Burbank, East Pasadena, East San Gabriel, Glendale, Monterey Park, Pasadena, San Gabriel, South Pasadena and Temple City.
Of the 98,057 sentences that were assessed, 6% (6,089) were identified as boilerplate. A classification algorithm27 was then trained on this dataset, using both each sentence’s location in its originating document, as well as character28 and word29 features to make the determination. Finally, a custom set of binary regular expression pattern flags were added as additional features, based on a list of indicators that researchers identified to be commonly associated with boilerplate sentences.30
The resulting model correctly identified known boilerplate sentences 88% of the time (recall), and the sentences it flagged agreed with researcher labels 86% of the time (precision). This level of accuracy was sufficient to facilitate deduplication.
Of the final set of documents used in this analysis, 65.8% had some of their text removed during this process, across 542 different members of Congress.31 Among those that were modified, 6.6% of the text was removed on average,32 with a median of 1.2%.
Fixing incorrect dates
As a first pass in correcting errant dates, researchers reviewed outliers. A number of dates stood out on which a highly disproportionate number of press releases appeared to have been published. Researchers iterated over all unique politician, source (LexisNexis or website), and date combinations, and examined any that had more than ten press releases issued by a single politician on a single day, all from the same source. Researchers found 41 such combinations for the timeframe covered by this report. For each combination, researchers then randomly selected three documents for manual review. When an incorrect date was found, researchers attempted to determine the nature of the error and codify a rule for making a correction.
Correcting dates in press releases collected from member websites
Several systematic inaccuracies found in press releases collected directly from members’ websites resulted in errant dates being associated with each release. The process used to identify and remedy these issues is detailed below.
Releases for four politicians had systematic time-stamp errors, but all four included the correct dates in the first sentence of each press release. Researchers extracted the correct dates using regular expressions.33
The most common cause of errant dates was “archive dumping.” Archive dumping occurs when a large collection of older press releases from a prior version of a politician’s website was transferred to their latest website, and dated by the transfer date rather than the original publication date. This affected 16 politicians, spanning 25 different dates. For 21 of those dates, press release dates were cleared entirely. For the remaining four dates, all press releases occurring on or before that date were cleared. There were systematic errors for prior dates as well. However, the vast majority of these cases occurred prior to the timeframe in this report – only 162 of the press releases used in this study were impacted by these issues (151 dates were cleared, and 11 were corrected). As a precautionary measure, dates were cleared out for all of the press releases that occurred on the first available date for each politician, in order to avoid any remaining archive dumps that may have been missed.
LexisNexis dates did not appear to have significant errors. In some cases the LexisNexis dates lagged behind those on the website, however, this did not hamper the deduplication process.
Identifying and removing duplicates
In order to compare documents against each other and consolidate copies of press releases, documents were first grouped by their associated politician. Each politician’s set of press releases was then parsed, tokenized and represented as a term frequency-inverse document frequency (TF-IDF) matrix. Documents were compared against all other documents, and any pair with a cosine similarity of at least 0.70 were grouped together as potential duplicates. For each such group, each press release was compared against the others once again and the set was then grouped into even smaller subsets based on whether or not a pair of documents had a Levenshtein distance ratio of at least 0.70.
A number of issues necessitate additional processing to detect duplicate press releases. First, politicians occasionally reuse content across their press releases – using boilerplate press releases for announcements related to a particular topic area, for example, where only a few words might change between a press release announcing the introduction of a bill and a release announcing its passage several months later. Announcements of grant funding are another common pattern, in which an entire press release will essentially be copied-and-pasted multiple times with the dollar amount and recipient being the only substantive variations.
Hence, two nearly identical press releases may be similar, but still distinct. Dates can often be helpful in making this determination, but a pair of duplicates collected from different sources might not have exact date matches. A release may have taken a day or two to make its way from a politician’s press office, to a wire service, and then to LexisNexis.
After a manual examination of potential remaining duplicates, it was clear that a machine-learning approach would be necessary to identify remaining duplicates for removal. A random forest classifier was trained on the coded sample, scored on recall, and assessed on a 25% hold-out from the sample.34 Features included: full and partial Levenshtein ratios for a pair of documents, and for each metric, the difference between the two; indicators of whether the two documents had the same day, month, and day/month combination; the total difference between the dates in days; whether or not the documents were from the same source; for each source, whether at least one of the two documents was from that source; whether the documents’ text matched completely; and the length of the shortest document, the longest document and the character difference in text length between the two. Additional regular expressions that might indicate false positives were also included, representing keywords that tend to vary in otherwise identical releases.35 The resulting model achieved 93% precision and 92% recall in identifying false positives (non-duplicates), and 96% precision and 97% recall in identifying true positives (correct duplicates).
This approach was used with every set of politicians’ press releases and press release pairs that were identified as duplicates were consolidated as a single document. If one press release had more complete metadata than another, the missing fields were filled in. If the two press releases had a date conflict, the earlier date was chosen as the correct one. This occurred frequently when website press releases were matched to LexisNexis duplicates, the latter of which often had dates trailing the former by several days.36
Prior to deduplication, 87,362 press releases were collected from congressional webpages, and an additional 234,534 were collected from LexisNexis. This resulted in a total of 321,896 press releases from both sources. During deduplication, 5,119 duplicates were found among the webpage-based press releases themselves, an additional 145,485 duplicates were found within the LexisNexis press releases themselves, and 75,248 LexisNexis press releases were dropped in favor of duplicates found amongst the webpage versions. A total of 225,852 press releases were removed, resulting in a final collection of 96,064 remaining press releases. In all, 85% of the press releases collected from webpages were also found in LexisNexis, and 92% of the press releases collected from LexisNexis were also found on congressional webpages. A random sample of 50 remaining LexisNexis articles were examined by researchers to confirm that they did not represent missed duplicates. All articles reviewed were determined to be press release content that was missed during the website data collection process, most commonly because a representative had posted the release in a different section of their website, separate from other press releases.
Other data sources
Researchers also used two datasets containing contextual information about individual legislators: DW-NOMINATE ideology estimates and 2012 presidential election results. Ideology estimates are publicly available at Voteview.org. Researchers obtained election results at the level of states and congressional districts in the replication materials for Gary Jacobson’s “It’s Nothing Personal: The Decline of the Incumbency Advantage in U.S. House Elections,” published in the Journal of Politics. The replication materials are also available online.
Content analysis
Codebook
After finalizing the collected data, researchers developed a codebook or classification scheme for human analysts to classify documents. This codebook differs from most in that all variables are binary, indicating the presence or absence of the content in question.
To assess political disagreement, the following measure was coded: “Does the document express opposition toward or disagreement with any of the following?” followed by a list of political targets. The first, President Obama or his administration, was defined as: “The president himself or one of his own decisions and actions, or those of his administration.” Coders were instructed to look for the terms “Obama,” “The President,” “the or this Administration,” “The White House,” and “executive,” in the context of actions or decisions. Coders were instructed to avoid policy terms like “Obamacare” and mentions of federal agencies that were not explicitly linked with the president.
The second political target was “Democrats (other than Obama), or ‘liberals’ in general.” For that item, coders were told to look for the words “Democrats,” “DNC,” “liberals,” “left-wing,” “progressives” and any elected official identified as a Democrat, but to avoid references to the president, unions, activist groups like Occupy Wall Street, and other organizations that are not formally linked with the party. Third, coders identified disagreements with “Republicans, or ‘conservatives’ in general” by looking for the terms “Republican,” “RNC,” “conservative,” “right-wing,” “Tea Party” and any elected official described as a Republican. Coders were instructed to avoid coding religious groups, advocacy groups or general ideologies such as “conservatism” as Republican targets, unless the document explicitly linked them to Republican politicians.
To assess political indignation, researchers instructed coders to identify whether “the document expresses any indignation or anger,” by evaluating strong adjectives, negative emotional language and resentment. Coders were instructed to look for language that “expresses a degree of anger, resentment, or indignation,” alongside conflictual terms like “fight” and “attack,” as well as moral imperative statements. Coders were told to avoid coding disagreement that lacked emotional rhetoric as indignation. Researchers provided a list of examples of indignation, such as “President Obama’s foreign policy is irresponsible, shortsighted and DANGEROUS” and “Instead of being honest and upfront about their goals, the Republicans have used a number of budgetary gimmicks to cover-up the devastating impact that their budget will have on the lives of ordinary Americans ….” Examples of non-indignant text included: “discrimination has no place in our federal government” and “I have serious concerns those requirements were not met.”
Bipartisanship references were identified as cases in which “the document mentions one or more members of both parties agreeing on something or working together in a bipartisan manner.” Specifically, researchers described how the text must “mention some way in which Republicans or Democrats have agreed, worked together, or compromised, are currently doing so, or will be in the future,” and that statements opposed to bipartisanship did not qualify. Examples of bipartisanship included: “Both Republicans and Democrats agree: the President must work with Congress on any Iran deal,” “The only reason that Mr. Boehner was able to get his two-year deal in the first place was with overwhelming Democratic support. It would be unwise to wander too far from that bipartisan framework,” and “President Obama will veto a bipartisan defense bill to coerce more domestic spending.”
To capture statements about government benefits, coders were instructed to determine whether “the document mentions a specific benefit for people in the district.” These references could include “current or future, real or hypothetical benefits for a local constituency, often regional or local investment,” but they could not be announcements related to local meetings or town halls unless they were related specifically to a benefit. As examples of references to benefits, coders read the following: “I am thrilled to join with College Possible and College Possible Philadelphia in celebrating their $3 million innovation grant award from the U.S. Department of Education” and “My vote to protect Joint Base McGuire-Dix-Lakehurst and our national defense programs… Sources have said the loss of the tankers would be devastating to the joint base, which is Burlington County’s largest employer.” Coders were instructed to avoid vague references to benefits, such as “Thanks to the Northmoreland Township Volunteer Fire Company for the opportunity to tour its headquarters and discuss my legislation to protect local fire companies from Obamacare with its members.”
The complete classification list follows:
- Does the document mention a specific benefit for people in the district?
- Does the document discuss a foreign policy or international issue?
- Does the document mention one or more members of both parties agreeing on something or working together in a bipartisan manner?
- Does the document describe the U.S. political system/process or government as broken, corrupt, wasteful, or dysfunctional?
- Does the document express any indignation or anger?
- Does the document express opposition toward or disagreement with any of the following? (Select all that apply)
- President Obama or his administration
- Democrats (other than Obama), or “liberals” in general
- Republicans, or “conservatives” in general
- A specific federal agency or regulatory group
- A court or court decision
- An advocacy group, union, industry, or private company
- The media or a news outlet
Document samples for hand coding
Because exploratory random sampling showed that disagreement and indignation were relatively rare, a set of keywords representing various political targets were used to over-sample documents more likely to contain attacks or criticism to ensure that enough positive cases would be present for machine learning. This was accomplished using four different regular expressions:

Random samples of documents were then collected, which were stratified across pattern-matched content categories, members of Congress, and party. Oversampling low-incidence strata increased the number of positive cases available for training, which resulted in substantially higher model accuracy (particularly for recall).
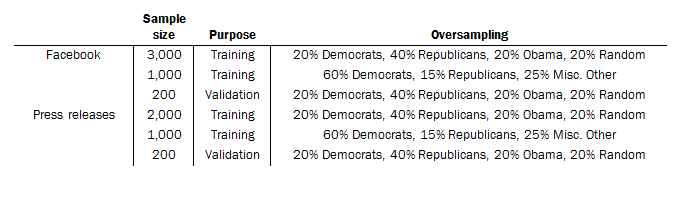
Crowd-sourced document classification
To classify the content of Facebook posts and press releases, researchers employed coders from Amazon’s Mechanical Turk. Only Mechanical Turk workers who earned Amazon’s “Masters” certification and had an account associated with an address in the United States were eligible to classify the documents. In all, 3,200 press releases and 4,200 Facebook posts were each coded by five unique coders between July 8 and Aug. 22, 2016. Coders were paid $0.30 per press release and $0.20 per Facebook post. The median worker submission took 51 seconds to classify a Facebook post, and 79 seconds to classify a press release. The median hourly rate for online workers was $13.67 for press releases and $14.12 for Facebook posts.
Each Mechanical Turk worker who agreed to code a set of documents was also asked to complete a brief survey of their political views and basic demographic information in order to qualify for the work. After completing the qualification survey, coders then used a custom online coding interface embedded within the Amazon Mechanical Turk assignments to classify each Facebook post and press release. The creation of coding assignments, as well as the process of downloading and compiling the results, was accomplished using the Amazon API directly.
Validating the crowd-sourced data
In order to assess the validity of the crowd-sourced document classifications, two researchers manually coded the same 200 press releases and 200 Facebook posts that a set of Mechanical Turk coders also classified for comparison.37
Internal agreement between Pew Research Center’s two experts was then assessed, after which the coders reviewed cases where they disagreed to arrive at a consensus. Accordingly, a single consolidated expert code for each document was generated and compared to the Mechanical Turk workers’ codes (aggregated as described below) and the final machine learned codes.
Researchers found little evidence that coding decisions were related to coder partisanship or ideological identification. Both attributes of coders had no substantively or statistically significant relationship with the classification decisions we examine here.
In order to aggregate all five Mechanical Turk workers’ responses into a single set of codes, for each variable, researchers computed a threshold for the number necessary to infer that the document contained the content in question. This was accomplished in via the following steps.
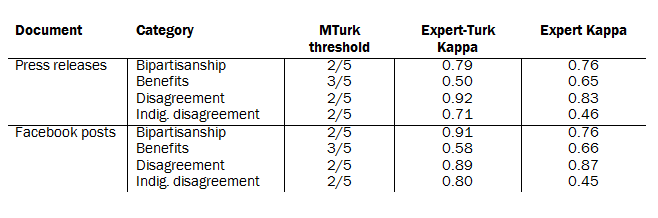
First, using the internal codes arrived at by the Center’s experts as a comparative baseline, researchers selected candidate thresholds for aggregating the crowd-sourced codes (i.e. the proportion of Turk coders required to consider a case “positive”) that either maximized agreement for each indicator variable (Cohen’s Kappa), or produced agreement that was within the standard error of the maximum. This was done for each indicator variable for Facebook posts and press releases separately.
Second, to maximize the comparability of the key measures across both Facebook posts and press releases, for each variable, any candidate thresholds that were not shared between both document types were discarded from consideration. This resulted in a single threshold for each key variable, with the exception of the three disagreement items. Since these disagreement items were similar in nature and were to be compared and grouped together during analysis, researchers selected the single remaining threshold shared in common across these three measures.
After finalizing the consolidation thresholds for each classification variable, the selected cutoffs were used to aggregate the Mechanical Turk codes for each document in the (full) training sample for both press releases and Facebook posts.
To produce the variables used in the actual report, researchers first created a “disagreement” variable that was positive if any of the three disagreement categories (disagreement with the president, disagreement with Democrats, disagreement with Republicans) was positive (indicating its presence in the document). Researchers then created an “indignant disagreement” variable that was positive if both indignation and disagreement were positive.
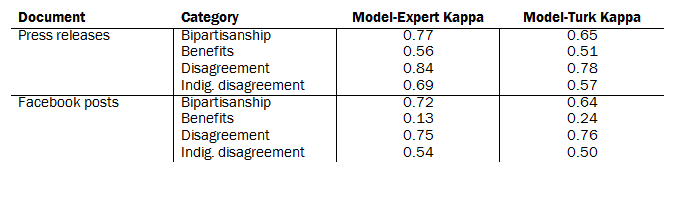
To produce a single measure of inter-rater reliability for all measures used in the report, researchers concatenated all codes for each document using the consolidated categories for internal coders and comparing to the consolidated categories for Mechanical Turk workers. For Facebook posts, the combined Cohen’s Kappa was 0.78; that number was 0.61 for press releases. The higher level of accuracy for Facebook is a result of excluding the “constituent benefit” category, whose incidence on Facebook was too infrequent to include in the analysis. Cohen’s Kappa between the Center’s expert two coders was 0.59 for Facebook and 0.57 for press releases. Levels of agreement for specific categories are provided in the table below.
Cleaning the text
To produce a dataset useful for machine learning, the text of each document was converted into a set of features, representing words and phrases. To accomplish this, each document was passed through a series of pre-processing functions (on top of the cleaning and deduplication steps outlined above). First, to avoid including words that could bias the machine-learning models towards particular politicians or districts, a set of custom stopword lists were used to filter out names and other proper nouns, comprised of the following:
- A list of 318 common English stopwords, taken from the Glasgow Information Retrieval Group
- A list of 9770 first and last names, taken from a Pew Research Center database of 13,942 current and historical politicians, and filtered using WordNet
- A list of 896 state names and state identifiers (e.g. “West Virginian”, “Texan”)
- A list of 18,128 city and county names, taken from a Pew Research Center database of geocoded campaign contributions, and filtered using WordNet
- A list of 24 month names and abbreviations
- 331 additional stopwords, manually identified through a process of iterative review by Center researchers
Some people and locations have names that are also common English words, some of which are used far more frequently as the latter. To avoid unnecessarily excluding these words from our training data, potential stopwords were assessed using WordNet, which provides information on a word’s alternative definitions and where they fall on a spectrum of generality to specificity (using a hyponymy taxonomy). If a word met two or more of the following criteria, it was flagged as being common and/or versatile enough to be included in the training data, and was removed from the stopword list:
- The word has more than two different definitions (synsets)
- One or more of the word’s definitions (synsets) had a variation (lemma) with a depth of less than five (indicating generality)
- One or more of the word’s definitions (synsets) had at least two variations (lemmas)
After combining all of these lists into a single set of stopwords, an additional 66 words were removed, based on a list compiled by Center researchers during a process of manual iterative review. This ultimately resulted in a list of 27,579 stopwords that were removed from the text of all documents. After removing stopwords, the text of each document was lowercased, and URLs and links were removed using a regular expression.38
Common contractions were expanded into their constituent words, punctuation was removed and each sentence was tokenized using the resulting whitespace. Finally, words were lemmatized (reduced to their semantic root form), and filtered to those containing three or more characters.
Extracting features
Machine-learning models were trained on term-frequency inverse-document frequency matrices, containing 1 to 4 grams with a minimum document frequency of 10 and maximum document proportion of 90%. In addition to a matrix constructed from each document in its entirety, a subset of classifiers also utilized matrices produced from a subset of sentences that contained keywords relevant to the classification variable, identified using regular expressions:
- Bipartisanship: sentences that contained a match on [Bb]ipartisan*
- Disagreement with Obama: sentences that matched on the Obama regular expression used for oversampling
- Disagreement with Democrats: sentences that matched on the Democrat regular expression used for oversampling
- Disagreement with Republicans: sentences that matched on the Republican regular expression used for oversampling
- Constituent benefits: sentence that contained the name of a state, or matched on [Ll]ocal|[Dd]istrict*|$([0-9]{1,3}(?:(?:,[0-9]{3})+)?(?:.[0-9]{1,2})?)s
Additionally, the constituent benefit classifier also utilized counts extracted from the text using the following three regular expressions, representing common patterns related to monetary amounts:
- r’$([0-9]{1,3}(?:(?:,[0-9]{3})+)?(?:.[0-9]{1,2})?)s’
- r’$[0-9]{1,3}((,[0-9]{3})+)?s’
- “thousand*|million*|billion*|hundred*”
Model training
Machine-learning algorithms were then used to classify the entire scope of documents used in this report based on these training results from human coders.39 The relevant classification models, called Support Vector Machines (SVMs), use information about the known relationships between particular words and classification decisions in human-coded texts (training data) in order to classify texts that are not already coded (test data). The use of machine-learning models mitigates the cost and time that would be required to use human-based methods to classify the entire range of Facebook posts and press releases.
SVMs were trained on these features for each classification variable and document type, hyper-parameterized over different penalty levels40 and kernels41 with 5-fold cross-validation. The best parameters were selected using Matthew’s correlation coefficient as the scoring function. Training data was weighted and evaluated using traditional sample weighting based on the population proportions of over-sampled keywords (their true value across the range of documents to be studied in this report). Additional weights were used only during the model training process (not during evaluation), weighting cases using the inverse proportion of their class and balanced across party lines using weighted proportions (artificially adjusted to 50%) so that each political party was given equal consideration by the algorithm.42 After training, the models were evaluated by comparing them to the 200 validation cases for their respective document type, as well as to their 5-fold cross-validation averages.43
The following table shows the performance for each model:
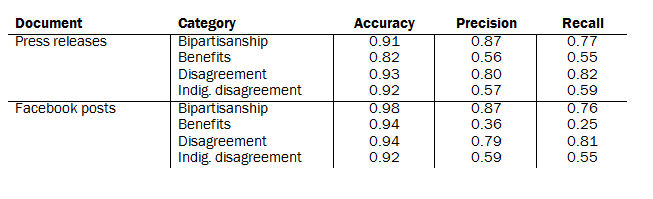
Reliability statistics comparing the hand-coded data to these machine-learned measures follows:
The final resulting population means for the model-based measures used in this report are reported below, compared against the sample means from Mechanical Turk.
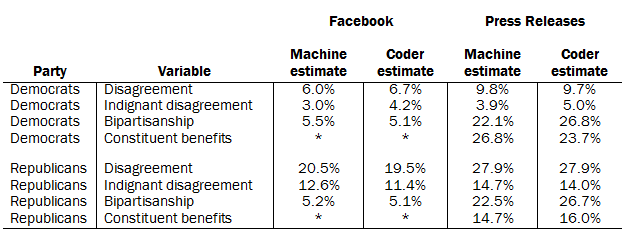
* Since constituent benefits-related Facebook posts were rare and difficult to classify, we excluded them from this and all other analyses.
Overall, the model estimates of disagreement, indignant disagreement, bipartisanship and constituent benefits are comparable to those observed in the sample of documents classified by Mechanical Turk workers.
Multivariate analysis of Facebook engagement metrics
Random effects analysis of Facebook engagement
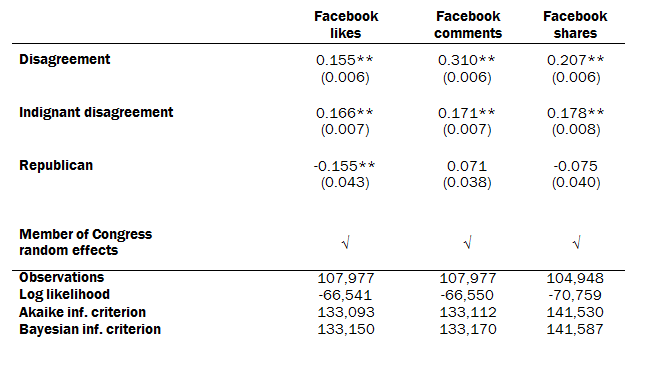
This Facebook-post level analysis shows that disagreement and indignant disagreement systematically predict additional Facebook likes, comments and shares. The number of likes, comments and shares used in this analysis is logged (base 10) due to the skewed distribution of each measure. The model includes an intercept for each member of Congress, which helps account for the underlying popularity of a given member’s posts.
Fixed effects analysis of Facebook engagement
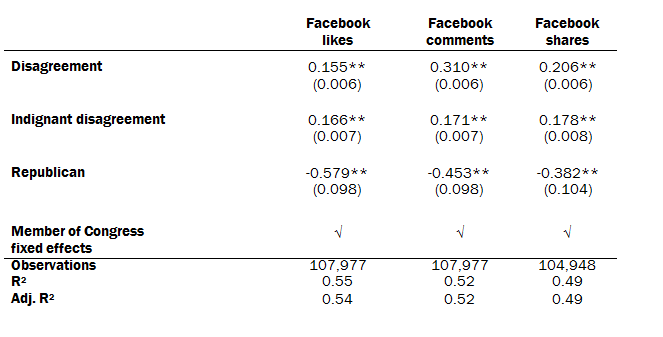
This Facebook-post level analysis verifies that disagreement and indignant disagreement systematically predict additional Facebook likes, comments and shares. The number of likes, comments and shares used in this analysis is logged (base 10) due to the skewed distribution of each measure. The model includes a dummy variable, or fixed effect, for each member of Congress. This is another way to account for the underlying popularity of a member’s posts.
Multivariate analysis of communications content
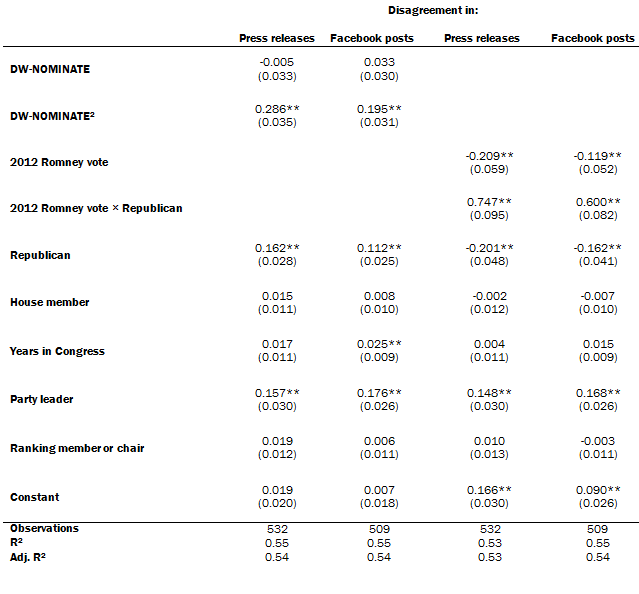
Ordinary least squares: Predicting the proportion of disagreement
This member of Congress-level analysis shows the attributes of individual elected officials that are associated with a higher proportion of expressed disagreement in press releases and Facebook posts. Ideological distance from the midpoint of DW-NOMINATE and district competitiveness are strongly associated with a higher proportion of disagreement.
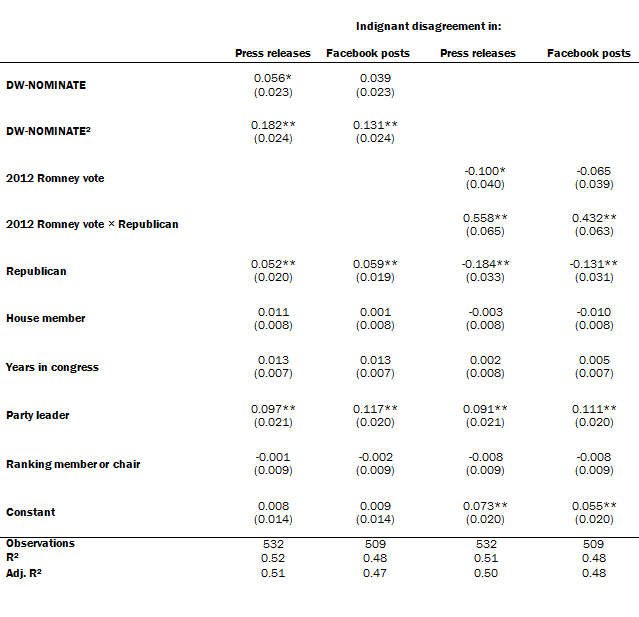
Ordinary least squares: Predicting the proportion of indignant disagreement
This member of Congress-level analysis shows the attributes of individual elected officials that are associated with a higher proportion of expressed indignant disagreement in press releases and Facebook posts. The patterns largely match those for expressions of disagreement without indignation.
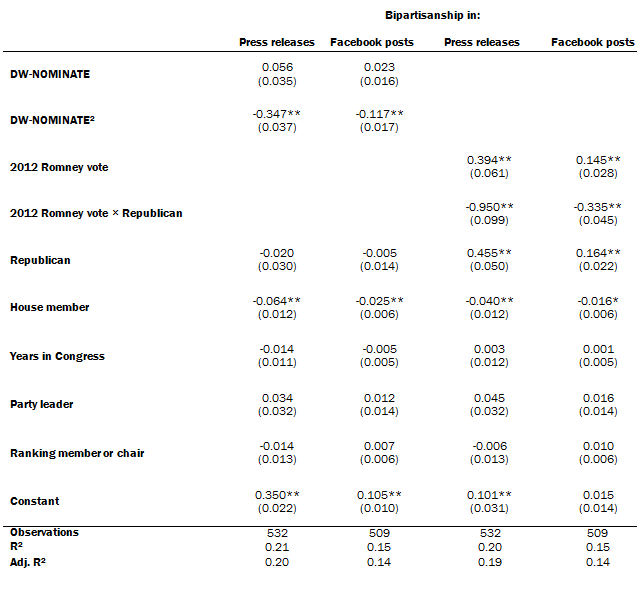
Ordinary least squares: Predicting the proportion of bipartisanship
This member of Congress-level analysis shows the attributes of individual elected officials that are associated with a higher proportion of bipartisan references in press releases and Facebook posts. Ideological moderation is strongly associated with bipartisanship, and House members appear less likely to focus on bipartisanship than their Senate colleagues.