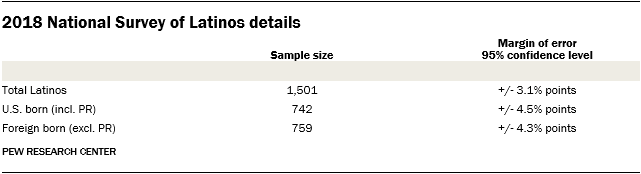
Results for this study are based on telephone interviews conducted by SSRS, an independent research company, for Pew Research Center among a nationally representative sample of 1,501 Latino respondents ages 18 and older. It was conducted on cellular and landline telephones from July 26 through September 9, 2018.
For the full sample, a total of 742 respondents were U.S. born (including Puerto Rico), and 759 were foreign born (excluding Puerto Rico). For results based on the total sample, one can say with 95% confidence that the error attributable to sampling is plus or minus 3.1 percentage points.
For this survey, SSRS used a staff of bilingual English- and Spanish-speaking interviewers who, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or English. A total of 626 respondents (41.7%) were surveyed in Spanish, and 875 respondents (58.3%) were interviewed in English. Any person age 18 or older who said they were of Hispanic/Latino origin or descent was eligible to complete the survey.
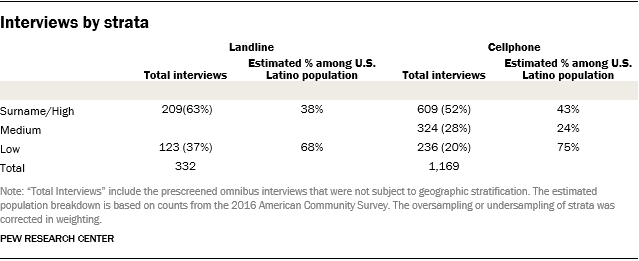
For the landline sampling frame, the sample was compared with InfoUSA and Experian landline household databases, and phone numbers associated with households that included persons with known Latino surnames were subdivided into a surname stratum. The remaining, unmatched and unlisted landline sample was used to generate a stratum with a high incidence of Latinos, based on the share of Latinos in the sample telephone exchange.
It is important to note that the existence of a surname stratum does not mean the survey was exclusively a surname sample design. The sample is RDD (random-digit dial), with the randomly selected telephone numbers divided by whether or not they were found to be associated with a Spanish surname. This was done to ease administration by allowing for more effective assignment of interviewers and labor hours, as well as increase the efficiency of the sample.
MSG’s GENESYS sample generation system was used to generate cellphone sample, which was divided into high and medium strata, based on the share of Latinos in the sample telephone area code.
Samples for the low-incidence landline and low-incidence cell strata were drawn from previously interviewed respondents in SSRS’s weekly dual-frame omnibus survey. Respondents who indicated they were Latino on the omnibus survey were eligible to be recontacted for the present survey. Altogether, a total of 359 previously interviewed respondents were included in this sample.
A multistage weighting procedure was used to ensure an accurate representation of the national Hispanic population.
- An adjustment was made for all persons found to possess both a landline and a cellphone, as they were more likely to be sampled than were respondents who possessed only one phone type. This adjustment also took into account the different sampling rate in the landline and cellphone samples.
- The sample was corrected for a potential bias associated with recontacting previously interviewed respondents in low-incidence strata.
- The sample was corrected for within-household selection in landline interviews, which depended upon the number of Latino adults living in the household.
- The sample was corrected for the oversampling of telephone number exchanges known to have higher densities of Latinos and the corresponding undersampling of exchanges known to have lower densities of Latinos.
- The listed cellphone sample was balanced back to the true distribution of listed cellphone sample in the cellphone RDD frame.
- Finally, the data were put through a post-stratification sample-balancing routine. The post-stratification weighting used estimates of the U.S. adult Hispanic population based on the 2016 U.S. Census Bureau’s American Community Survey, on gender, age, education, Census Bureau region, heritage and years in the U.S. Phone status of the U.S. adult Hispanic population (i.e., cellphone only, dual, landline only) is based on estimates from the July-December 2017 National Center for Health Statistics’ National Health Interview Survey and density of the Latino population is from the 2010 Census.
- Weights are then trimmed to avoid any particular case having too much influence on the overall estimates.
Pew Research Center undertakes all polling activity, including calls to mobile telephone numbers, in compliance with the Telephone Consumer Protection Act and other applicable laws.
Pew Research Center is a nonprofit, tax-exempt 501(c)(3) organization and a subsidiary of The Pew Charitable Trusts, its primary funder.