Asian Americans constitute a growing, but still rare population. According to the 2010 U.S. Census, Asian Americans constitute 5.6% of the U.S. population (and 5.5% of adults 18 years of age and older). The Asian-American population is dispersed throughout the country, although about half live in the Western region. Many Asian Americans are recent immigrants from multiple countries with differing native tongues who likely have difficulty completing a public opinion survey in English. Although the Asian-American population is quite diverse, the six largest Asian subgroups—Chinese, Filipino, Indian, Vietnamese, Korean and Japanese—represent 84.9% of all U.S. Asian adults.100
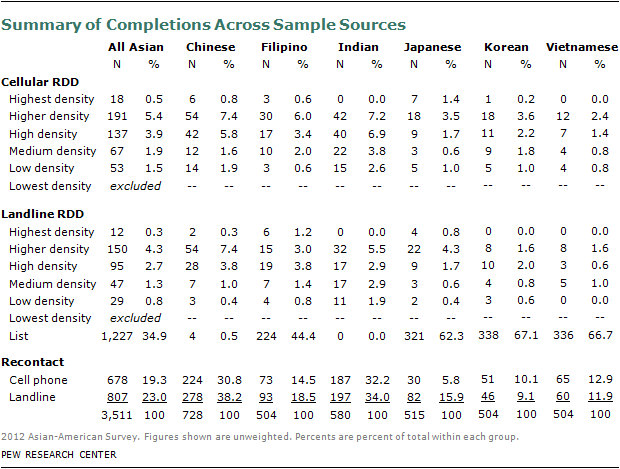
Despite these challenges, the Pew Research Center 2012 Asian-American Survey was able to complete interviews with 3,511 Asian-American adults 18 years of age and older living in the United States from a probability sample consisting of multiple sample sources that provided coverage for approximately 95% of the Asian-American population. The survey was conducted in all 50 states, including Alaska and Hawaii, and the District of Columbia. The survey was designed not only to represent the overall Asian-American population but also the six largest Asian subgroups (who each represent 0.4% to 1.3% of the adult U.S. population). Interviews were completed with 728 Chinese, 504 Filipinos, 580 Asian Indians, 515 Japanese, 504 Koreans, 504 Vietnamese and 176 Asians of other backgrounds.
Respondents who identified as “Asian or Asian American, such as Chinese, Filipino, Indian, Japanese, Korean or Vietnamese” were eligible to complete the survey interview, including those who identified with more than one race and regardless of Hispanic ethnicity. The question on racial identity also offered the following categories: white, black or African American, American Indian or Alaska Native, and Native Hawaiian or other Pacific Islander.
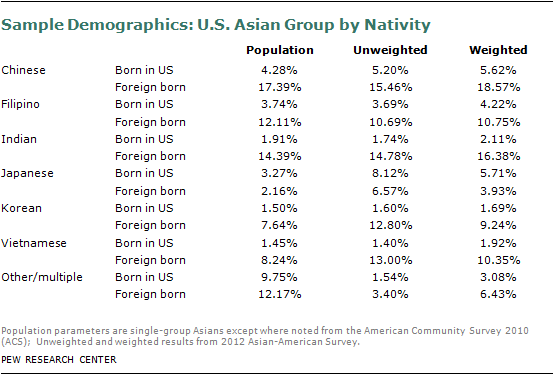
Classification into U.S. Asian groups is based on self-identification of respondent’s “specific Asian group.” Asian groups named in this open-ended question were “Chinese, Filipino, Indian, Japanese, Korean, Vietnamese, or of some other Asian background.” Respondents self-identified with more than 22 specific Asian groups. Those who identified with more than one Asian group were classified based on the group with which they identify most. Respondents who identified their specific Asian group as Taiwanese or Chinese Taipei are classified as Chinese-Americans for this report. See the questionnaire for more details.
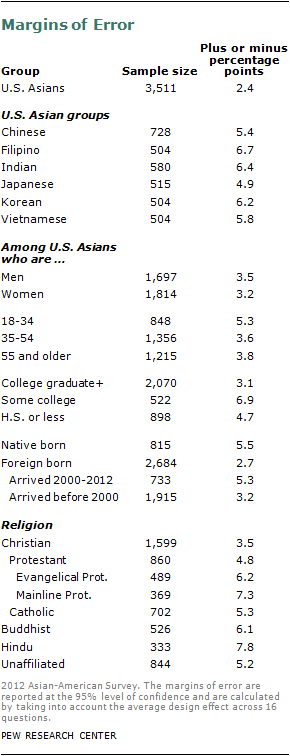
Interviewing was conducted from Jan. 3 to March 27, 2012 by Abt SRBI. Interviews were conducted in English as well as Cantonese, Hindi, Japanese, Korean, Mandarin, Tagalog and Vietnamese. After taking into account the complex sample design, the average margin of sampling error for the 3,511 completed interviews with Asian-Americans is plus or minus 2.4 percentage points at the 95% level of confidence. The following table shows the sample sizes and margins of error for different subgroups of Asians in the survey:
Sample Design
The sample design aimed to address the low incidence and diversity of the Asian-American population while still achieving a probability-based sample by employing multiple sampling frames, including landline and cell phone random-digit-dial (RDD) samples and a sample of previously identified Asian households. In addition, to complete a sufficient number of interviews with the lowest incidence U.S. Asian groups, ethnic name based lists of “probable” Filipino, Korean, Japanese, and Vietnamese households maintained by Experian were used.101
RDD Geographic Strata
Since the number of Asian Americans in national landline and cell RDD frames is quite low, the landline and cell samples were geographically stratified to improve the efficiency of the interviewing, where phone numbers in areas with higher Asian-American incidence were selected at a higher rate than phone numbers in areas with lower incidence. The differential selection rates were taken into account in the weighting, which is described later in this section.
The landline and RDD frames were divided into six stratum according to their incidence of net Asian Americans and Asian American subgroups based on county-level estimates from the U.S. Census Bureau’s American Community Survey (2007 to 2009 multi-year estimates). Counties were first grouped by the incidence of Asian Americans as follows: Highest Density (35% and above), Higher Density stratum (incidence 15% to 34.99%), High Density stratum (incidence 8% to 14.99%), Medium Density stratum (incidence 4% to 7.99%), Low Density stratum (incidence 1.5% to 3.99%) and Lowest Density stratum (incidence under 1.5%).
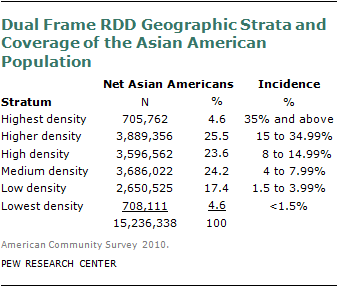
Then, an additional step was taken to see if counties should be reassigned to higher density strata if they have a relatively high density of one or more of the Asian subgroups. However, this step resulted in only minimal revisions to the initial stratification. Only four counties in the U.S. have Japanese incidence greater than 3% (they are all in Hawaii—Honolulu, Kauai, Maui, and Hawaii counties); these were assigned to the Highest Density stratum. Only three counties have Korean incidence greater than 3%; two were already in the Higher Density stratum (Fairfax Co., VA and Bergen Co., NJ) and the third (Howard Co., MD) was reassigned to the Higher Density stratum due to the relatively high incidence of Koreans. Two counties have Vietnamese incidence greater than 3% (Santa Clara Co. and Orange Co., CA); both of these were already in the Highest Density stratum. The Low, Medium, High, Higher, and Highest Density strata cover 95% of all net Asians in the United States.
In the Lowest Density Stratum, the incidence of Asian Americans is less than 1.5%. In order to keep costs contained, counties in this stratum—which are home to approximately 4.6% of all Asian Americans—were excluded from the landline and cell RDD samples. Asian Americans living in the Lowest Density stratum were still partially covered by the recontact and list samples.
Based on previous Pew Research studies with English and Spanish interviewing, the incidence of self-identified Asian Americans is approximately 1.5% in national landline RDD samples and 3.1% in national cell RDD samples. To determine how best to allocate interviews across the landline and cell frames, these estimates along with additional analysis of Asians encountered in the screening for Pew Research’s 2011 Muslim American Survey, were used to estimate the expected incidences of Asian Americans in each strata in both the landline and cell RDD frames. Based on these expected incidences, 60% of the RDD sample was allocated to the cell RDD frame and 40% to the landline RDD frame. In the final sample of completed RDD interviews, 58% were from the cell frame and 42% were from the landline frame.
List Strata
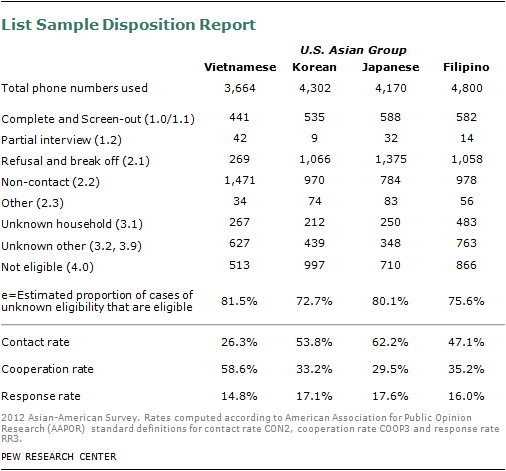
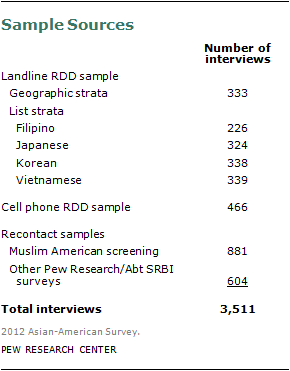
To reach the desired target of 500 completed interviews in each of the six largest U.S. Asian subgroups—Chinese, Filipino, Indian, Japanese, Korean and Vietnamese—the fresh RDD and recontact samples were supplemented with listed samples based on ethnic names. Because of the size of the U.S. Chinese and Asian Indian populations, list samples based on ethnic names were only needed for the other four subgroups—Filipinos, Japanese, Korean and Vietnamese.
In total, the list samples were used to complete interviews with 226 Filipinos, 324 Japanese, 338 Koreans and 339 Vietnamese.
The list samples were constructed from a commercial database of households where someone in the household has a name commonly found in that Asian subgroup. The lists were prepared by Experian, a commercial credit and market research firm that collects and summarizes data from approximately 113,000,000 U.S. households. The analysis of names was conducted by Ethnic Technologies, LLC, a firm specializing in multicultural marketing lists, ethnic identification software, and ethnic data appending services. According to Experian, the analysis uses computer rules for first names, surnames, surname prefixes and suffixes, and geographic criteria in a specific order to identify an individual’s ethnicity and language preference.
Such listed samples are fairly common in survey research, but when used alone they do not constitute a representative sample of each Asian subgroup and the probability that a given household belongs to one of these lists is not known. By combining these lists with the landline RDD frame, however, the lists can be used as components of a probability sample using statistical procedures that have been developed to incorporate these types of listed samples into probability-based surveys. The procedure implemented for this study involves obtaining the entire list maintained by Experian for listed landline households for Filipinos (n=140,163), Japanese (n=211,672), Koreans (n=164,710) and Vietnamese (n=274,839). These four lists can be defined as four strata within the entire landline RDD frame for the U.S. All telephone numbers drawn for the geographic strata of the landline frame were compared to the entire Experian lists for each of the four subgroups. Any numbers that appeared on the Experian list frames were removed from the geographic RDD sample and were available to be released only as part of the list strata. This method makes it possible to determine the probability that any given Asian American has of being sampled, regardless of whether he or she is included in the Experian lists. It also permits estimation of the proportion of all Asian Americans who are covered by the Experian lists, which in turn makes it possible to give cases from the Experian samples an appropriate weight. The list strata also provide some coverage of households in the Lowest Density stratum since numbers in counties belonging to that stratum and appearing on the Experian list were available to be sampled through the list samples.
In some cases, the person identified in a list sample did not belong to the nominal list group (i.e., either Filipino, Japanese, Korean, or Vietnamese). When this occurred, the interview was terminated and coded as ineligible. This protocol was motivated by considerations of weighting calculations and the overall design effect from weighting.
Recontact Frame
In order to obtain at least 500 interviews with each of the major Asian-American subgroups, the national dual frame RDD samples were supplemented with a sample of recontact cases. The recontact cases for this study came from several sources. In order to maintain the probability-based nature of the study, only recontact cases from prior national landline and cell RDD samples were used. Furthermore, additional steps were taken to account for the probabilities of selection in the original survey so that those could be reflected in the weighting for this survey.
All recontact numbers were checked against the Experian lists and the landline RDD and cell RDD samples and any numbers found were removed from those samples and only available to be released as part of the recontact sample. The recontact sample also provides some coverage of households in the Lowest Density stratum.
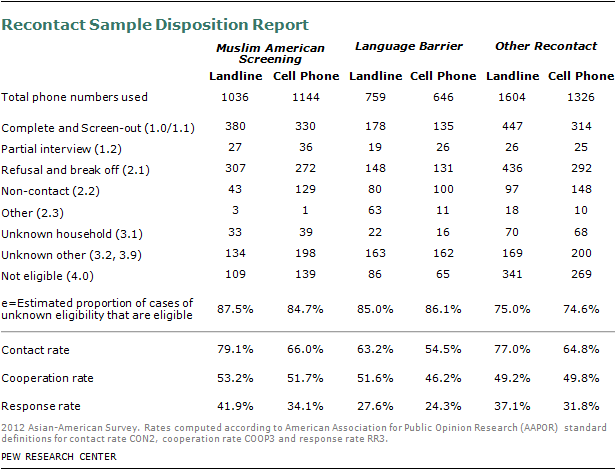
Two-fifths of the recontact interviews (604) came from self-identified Asian respondents from prior national dual frame RDD surveys conducted by the Pew Research Center or Abt SRBI since 2007. The remainder of the recontact sample came from the large, dual frame RDD telephone screening effort implemented for the 2011 Pew Research Muslim American Survey. All households identified as having a Muslim American in 2011 were excluded from the Asian American Survey sample in order to avoid the risk of context or conditioning effects. The 2011 Muslim American Survey entailed screening over 41,000 households, and of these 3,585 households were identified as likely having at least one Asian American adult and were not interviewed in the Muslim American survey.102 Since it was known at the time that cases from the Muslim American Survey would be used for the Asian American Survey, data was also collected on the specific Asian languages encountered as well as the ethnic groups to which screened, self-identified Asian Americans belong. The 3,585 recontact cases were of two general types: self-identified Asian American households and Asian language barrier households. The former group was comprised of 2,180 households in which a respondent completed the screener, reported a religious affiliation other than Muslim, and self-identified as Asian American to a question about racial identification. The latter group was comprised of 1,405 households where the screener was not completed, but the interviewer recorded that an Asian language speaker was encountered. A total of 601 interviews were completed with self-identified Asians and 280 interviews were completed with Asian language barrier households from the 2011 Muslim American Survey.
Questionnaire Development and Testing
The questionnaire was developed by the Pew Research Center. The development of the questionnaire was informed by feedback and advice from the panel of external advisors. In order to improve the quality of the data, the English questionnaire was piloted and then pretested with respondents using the Experian list sample.
Pilot Test and Pretest
For the pilot test of selected questions from the survey, 100 interviews were completed with Asian American adults sampled from the Experian lists. The interviews were conducted October 6-11, 2011. Among households completing the screener, the Asian incidence was 48%. The completion rate among qualified Asians was 76%. The average length for Asian households was 18 minutes. Based on the results of the pilot test, a number of changes were made to the questionnaire and interviewer training procedures. There was no monetary compensation for respondents for pilot interviews.
The pretest of the full survey resulted in 15 completed interviews with Asian-American adults sampled from the Experian lists. The interviews were conducted November 14, 2011. Among households completing the screener, the Asian American incidence was 65%. The extended interview completion rate among qualified Asian Americans was 68%. The average interview length for Asian households was 32 minutes. Additional changes were made to the questionnaire and interviewer training procedures based on the results of the pretest.
Translation of Questionnaire
Abt SRBI used a professional translation service for all translations. The initial translation used a three-step process of translation by a professional translator, back translation to English by a second translator, followed by proofreading and review for quality, consistency and relevance. As an additional quality control, the translated questionnaires were reviewed by a linguist from an independent translation service on behalf of the Pew Research Center. The translated questionnaires were compared to the English source document for accuracy of translation in the vernacular language. Discrepancies and differences of opinion about the most appropriate translation were resolved using an iterative process, with the original translator taking responsibility for reconciling all comments and feedback into the final translation.
Survey Administration
A six call design was employed for both landline and cell phone numbers with no callback limit for qualified Asian households. One attempt was made to convert soft refusals in the landline sample with no refusal attempts for the cell phone sample. Screening was conducted in English, with the exception of the Korean and Vietnamese list samples which were conducted by bilingual (English and Korean/Vietnamese) interviewers. Respondents speaking a foreign language were asked what language they speak. Respondents identified as speaking Mandarin, Cantonese, Korean, Vietnamese, Japanese, Hindi or Tagalog were transferred to an appropriate foreign language interviewer or called back by an interviewer who speaks the language if one was not immediately available.
All Asian respondents were offered $20 for their participation. Interviews were conducted in English (2,338 interviews), Cantonese (86 interviews), Mandarin (130 interviews), Vietnamese (382 interviews), Tagalog (80 interviews), Japanese (123 interviews), Korean (360 interviews) and Hindi (12 interviews). This was achieved by deploying 262 English-speaking and 14 foreign language-speaking interviewers. Only Korean and Vietnamese bilingual interviewers were assigned to the Korean and Vietnamese Experian samples. Calls were staggered over times of day and days of the week to maximize the chance of making contact with potential respondents.
All qualified callbacks and refusal landline cases which could be matched to an address were sent a letter encouraging participation in the survey. All language-barrier cases with an address were mailed letters translated into the appropriate language (Chinese, Korean, Vietnamese, Hindi, Japanese or Tagalog). A total of 1,131 letters were mailed.
Multilingual interviewers on staff were utilized for the project as well as newly recruited multilingual interviewers. New foreign language hires were first tested by an accredited firm on their language proficiency then evaluated and scored before being interviewed and hired by Abt SRBI. All multilingual interviewers first went through the standard Abt SRBI training process that all interviewers complete. Bilingual interviewers with more proficiency and interviewing experience were given coaching/team leader roles and worked with the interviewers in their language monitoring surveys, assisting in training and debriefing.
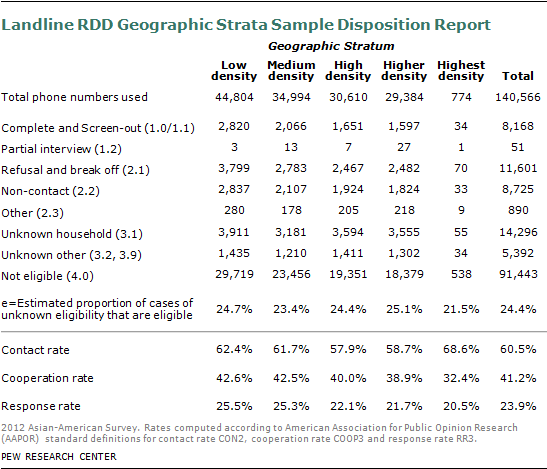
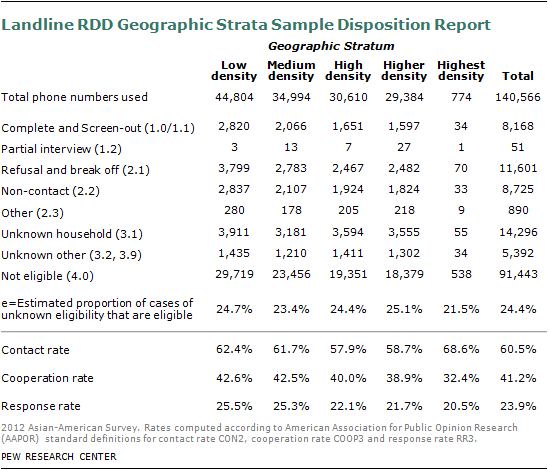
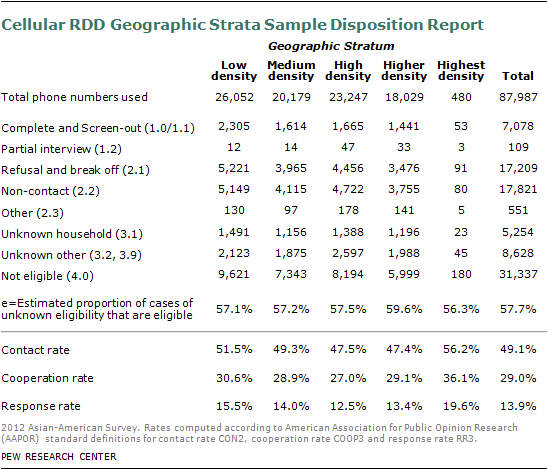
The screening effort yielded a response rate of 23% for the geographic landline RDD sample, 13% for the cell RDD sample, 14 to 18% for the list samples and 54-79% for the recontact samples, using the Response Rate 3 definition from the American Association for Public Opinion Research. The recontact sample response rates do not incorporate the response rates from the original surveys. Detailed sample disposition reports and response rates for each sample sources are provided in the supplemental tables.
The completion rate for qualified Asian respondents was 73% for the geographic landline RDD sample, 68% for the cell RDD sample, 84-92% for the list samples and 81-86% for the recontact samples.
Weighting
Several stages of statistical adjustment or weighting were needed to account for the complex nature of the sample design. The weights account for numerous factors, including (1) the geographic-based oversampling in the landline and cell RDD frames, (2) the selection rates in the four list strata, (3) the original probabilities of selection for the recontacts cases, (4) the presence of unresolved numbers in the sample (unknown eligibility), (5) nonresponse to the screener, (6) within household selection, (7) the overlap of the landline and cell RDD frames, (8) nonresponse to the extended interview, and (9) the limited coverage of the households in the Lowest Density stratum. Each of these adjustments is detailed below.
The first step in the weighting process was to account for the differential probabilities of selection of phone numbers sampled for the study. As discussed above, variation in the probabilities of selection came from several sources. In the landline and cell RDD geographic samples, numbers in counties with relatively high Asian American incidence were sampled at a higher rate than numbers in counties with lower incidence. Also, the numbers in the four list strata had selection probabilities higher than geographic RDD samples or the recontact sample. The probability of selection adjustment is computed as
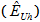
where Nh is the number of telephone numbers in the frame in stratum h, and nh is the number of telephone numbers from stratum h in the released replicates. For the landline and cell RDD geographic samples, stratum was defined by the cross-classification of frame (landline or cell) and geographic stratum (Low, Medium, High, Higher, Highest). For the four list samples, they each constituted their own stratum in the national landline RDD frame. For most of the recontact sample, stratum was defined as their sample (landline or cell) in the original survey. For the recontact cases from the 2011 Pew Muslim American Survey, stratum was defined by the cross-classification of frame (landline or cell) and geographic stratum as specified for that survey.
At the end of interviewing, each number dialed in the cell and landline geographic samples plus the list strata was classified as eligible (working, residential and not a minor’s phone), ineligible (non-working, business, or a minor’s phone), or unknown eligibility (busy/no answer all attempts, fax/modem/computer tone, answering machine/voice mail, or call blocked). For the recontact cases, this information was available from archived disposition reports for the original surveys. The base weights of the eligible cases were adjusted for the fact that some of the “unknown eligibility” cases are likely to have been eligible. This adjustment was performed by first computing the ratio of known eligible cases in the stratum (Eh) to the sum of known eligible and known ineligible cases in the stratum (Eh+Ih). This ratio was then multiplied by the number of unknown eligibility cases in the stratum (Uh) to yield an estimate for the number of eligible cases among those with unknown eligibility (
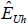
). The adjustment is then computed as
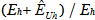
The next step was to adjust for nonresponse to the screener. The adjustment was computed as
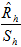
where
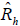
is the total count of telephone numbers in stratum h that are estimated to be residential and Sh is the number of completed screener interviews in stratum h. Note that
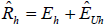
as suggested above.
Not all of the Asian-American adults identified in the screener completed the extended interview. An adjustment was performed by first computing the ratio of known qualified Asian-American cases in the stratum (Ah) to the sum of known qualified Asian American cases and screen-out (no Asian adults in household) cases in the stratum (Ah+Bh). This ratio was then multiplied by the number unscreened cases in the stratum (Ch) to yield an estimate for the number of qualified Asian American cases among those not screened (
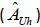
). The adjustment is then computed as
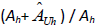
[randomized]
The base weights are the product of the aforementioned adjustments. The distribution of the base weights was examined for any extreme values. The distribution of base weight values for the recontact cases was noticeably different from the distribution of the base weight for the balance of the sample. The recontact cases had significantly larger base weights, on average, owing to smaller sampling fractions relative to the geographic RDD samples and list samples. Trimming of the base weights was, therefore, done separately for the recontact cases and the balance of the sample. In both instances, the threshold for trimming was the median + (6 x the interquartile range), which is common for major surveys with complex sample designs.
The next weighting step accounts for the overlap between the landline RDD frame and the cellular RDD frame. The dual service (landline and cell-only) respondents from the two frames were integrated in proportion to their effective sample sizes. The first effective sample size was computed by filtering on the dual service landline cases and computing the coefficient of variation (cv) of the final base weight. The design effect for these cases was approximated as 1+cv2. The effective sample size (n1) was computed as the unweighted sample size divided by the design effect. The effective sample size for the cell frame dual service cases (n2) was computed in an analogous way. The compositing factor for the landline frame dual service cases was computed as n1/(n1 + n2). The compositing factor for the cellular frame dual service cases was computed as n2/(n1 + n2).
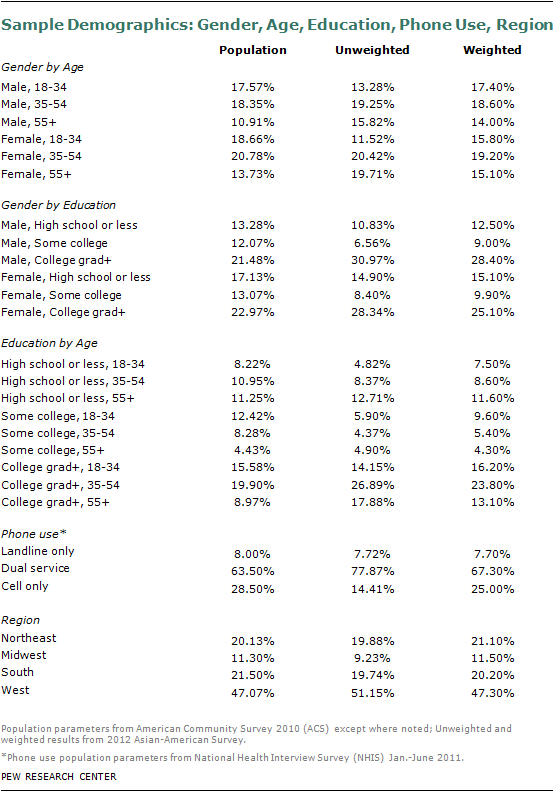
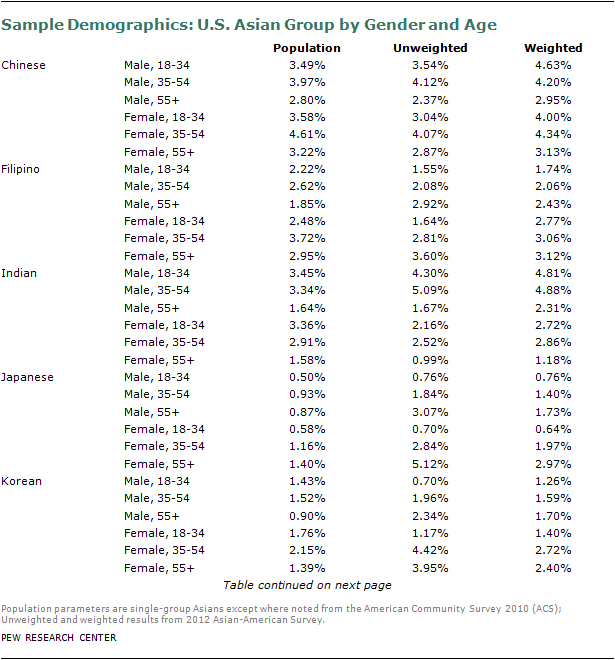
The survey sample was then balanced to population totals for the Asian-American adult population. The sample was balanced to match national net Asian American adult population parameters from the 2010 American Community Survey public use microdata sample (ACS PUMS) for gender by age, gender by education, education by age, region, ethnic group by nativity, ethnic group by gender by age, and ethnic group by gender by education. The ethnic group categories were Chinese alone, Filipino alone, Asian Indian alone, Japanese alone, Korean alone, Vietnamese alone, and Other Asian, including those that identify with more than one Asian group. In addition, the sample was balanced to Asian-American adult telephone service estimates from an analysis of the January-June 2011 National Health Interview Survey. The distribution of the calibrated weights was examined for any extreme values. The distribution of the final weights was truncated at the median + (6 x the interquartile range). This trimming was performed in order to reduce extreme variance in the weights and ultimately improve the precision of the weighted survey estimates. The sum of the final weights was set to equal the total number of net Asian-American adults based on the 2010 ACS PUMS.
Due to the complex nature of the 2011 Asian-American Survey, formulas commonly used in RDD surveys to estimate margins of error (standard errors) are inappropriate. Such formulas would understate the true variability in the estimates. To account for the complex design, a repeated sampling technique—specifically jackknife delete two repeated replication, JK-2—was used to create replicate weights for this study. The subsamples (replicates) were created using the same sample design, but deleting a portion of the sample, and then weighting each subsample up to the population total. A total of 100 replicates were created by combining telephone numbers to reduce the computational effort. A statistical software package designed for complex survey data, Stata v12, was used to calculate all of the standard errors and test statistics in the survey.
Supplemental Tables