Results for this study are based on telephone interviews conducted by ICR/International Communications Research, an independent research company, among a nationally representative sample of 1,540 Latino respondents ages 18 and older, from November 11 through November 30, 2008. Of those respondents, 622 were native born (including Puerto Rico) and 914 were foreign born (excluding Puerto Rico). The margin of error for total respondents is plus or minus 3.0 percentage points at the 95% confidence level. The margin of error for native-born respondents is plus or minus 4.8 percentage points at the 95% confidence level, and for foreign-born respondents it is plus or minus 3.8 percentage points.
For this survey, ICR maintained a staff of Spanish-speaking interviewers who, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or in English. A total of 546 respondents were surveyed in English and 976 respondents were interviewed in Spanish (and 18 equally in both languages). Any adult male or female of Latino origin or descent was eligible to complete the survey.
The sample frame was stratified via a disproportionate stratified design. All telephone exchanges in the contiguous 48 states were divided into groups, or strata, based on their concentration of Latino households. The sample was also run against InfoUSA and other listed databases, and then scrubbed against known Latino surnames. Any “hits” were subdivided into a “surname” stratum, with all other sample being put into other “RDD” strata. Overall, then the study employed five strata:
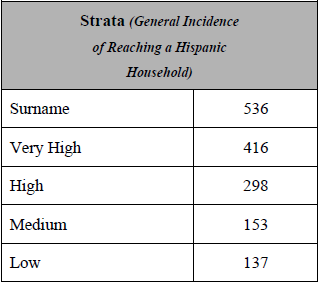
It is important to note that the existence of a surname stratum does not mean this was a surname sample design. The sample is random digit dial (RDD), with the randomly selected telephone numbers divided by whether they were found to be associated with or without a Latino surname. This was done simply to increase the number of strata and thereby increase the ability to meet ethnic targets and ease administration by allowing for more effective assignment of interviewers and labor hours.
Once collected, the data were corrected for the disproportionality of the stratification scheme described earlier. Then, the data were put through a post-stratification sample balancing routine. The post-stratification weighting utilized national 2008 estimates of gender, education, age, region, status as foreign born or native born, year of entry into the U.S. and Hispanic heritage, obtained from the Current Population Survey, March Supplement.






