The Pew Hispanic Center and the Pew Forum on Religion & Public Life conducted a public opinion survey among people of Latino background or descent on the topic of religion. The study was conducted via telephone by ICR, an independent research company based in Media, Pa. Interviews were conducted from Aug. 10 to Oct. 4, 2006 among a nationally representative sample of 4,016 Latino respondents age 18 and older. Of those respondents, 2,025 were Catholics and 905 were evangelical Protestants. The margin of error for the total sample is +/-2.5% at the 95% confidence level. The margin of error for Catholic respondents is +/- 3.3% at the 95% confidence level. The margin of error for evangelical respondents is +/-4.8% at the 95% confidence level.
For this survey, ICR maintained a staff of Spanish-speaking interviewers who, when contacting a household, were able to offer respondents the option of completing the survey in Spanish or in English. A total of 1,036 respondents were surveyed in English and 2,949 respondents were interviewed in Spanish, with the remaining 31 interviews conducted partly in English and partly in Spanish.
All interviews were conducted using a Computer Assisted Telephone Interviewing (CATI) system, which ensures that questions were asked in the proper sequence with appropriate skip patterns. CATI also allows certain questions and certain answer choices to be rotated, eliminating potential biases from the sequencing of questions or answers.
Eligible respondent
The survey was administered to any person age 18 and older who was of Latino origin or descent, though some screening was necessary to interview fewer Mexicans and fewer Central Americans (as described below). The survey used a modified most recent birthday method of selecting a respondent in each household; interviewers first asked to speak with the adult male in the household who had the most recent birthday, and if no male was available interviewers asked to speak with the adult female who had the most recent birthday.
Sampling methodology
A disproportionate stratified sample constructed using an optimal sampling allocation technique was used for the survey. A list of all telephone exchanges within a target area (national, by state, etc.) were sorted based on both concentration of Latino households and specific Latino heritage. The exchanges were then divided into various groups, or strata.
The primary stratification variables are the estimates of Latino household incidence and heritage in each area code and exchange combination as provided by the GENESYS System. These estimates are derived from Claritas, a marketing information company, and are updated at the telephone exchange level with each quarterly GENESYS database update. The basic procedure was to rank all area code and exchange combinations in the US by the incidence of Latino households and their ethnicity. This produced strata that were called Mexican, Puerto Rican, Cuban, Dominican, Central American, South American, High Latino, Medium Latino, and Low Latino. These strata were then run against InfoUSA and other listed telephone number databases, to identify households with known Latino surnames. Any households with Latino surnames were subdivided into ‘surname’ strata, with all other sample being put into ‘RDD’ strata.
Overall, the study employed 18 strata, 9 (Mexican, Puerto Rican, etc.) x 2 (surname/RDD). Two features of this design are worth noting. First, the existence of surname strata does not mean this was a surname sample design. The sample is RDD, with telephone numbers divided into strata according to whether or not they were found to be associated with a Latino surname. This was done simply to increase the number of strata (thereby increasing the ability to meet ethnic targets) and to ease administration (allowing for more effective assignment of interviewers and labor hours). Second, even though some strata were labeled by country of origin based on data base information, any Hispanic sampled from the stratum was accepted as a valid respondent for the study. For example, in a stratum called “Mexican,” both Mexicans and non-Mexicans who appeared in the stratum were interviewed.
For purposes of estimation, an optimal allocation scheme was employed. This “textbook” approach allocates interviews to a stratum proportionate to the number of Latino households, but inversely proportionate to the square root of the relative cost, the relative cost in this situation being a simple function of the incidence. As such, the number of completed interviews increases in moving from lower incidence strata to higher incidence strata. Again, this is a known, formulaic approach to allocation that provides a starting point for discussions of sample allocation and associated costs.
One of the major goals of the study was to attain sufficient numbers of non-Catholic Hispanics, since overall about a third of Hispanics say they are not Catholic. The study was designed so that in fact roughly 50% of all completes were from non-Catholics. This was done using two strategies. First, non-Catholics from all ICRconducted Pew studies from 2002 to the present were recontacted for this survey. Second, additional completes were obtained among non-Catholic Hispanics using the sample design described above.
Weighting and estimation
A two-stage weighting design was employed to ensure an accurate representation of the national Hispanic population. First all interviews that were attained of non-Catholics from prescreened sample (sample pulled from prior Pew studies) were analyzed to determine which strata they would have come from had they been interviews from the main study design. They were then temporarily assigned to those strata for weighting purposes. Then, all sample was rebalanced with a pre-weight to correct for the disproportionality of the stratified sampling design.
The file was then split into five main data files by Heritage (Mexican, Puerto Rican, Cuban, Central and South American, and Other). Each data file was put through a post-stratification sample balancing routine. The post-stratification weighting utilized national 2006 estimates from the Census and Claritas on age, gender, education, foreign/native born status and Catholic/non-Catholic status. As the Census is not allowed to ask about religion, counts for Catholic/non-Catholic status were based on the weighted percentages on religion found in all past ICR-conducted Pew Hispanic studies.
Each of the five data files was balanced to the proper proportion of its Heritage group based on national estimates. Thus, with 4,016 overall completes, the Mexican weighting run balanced to 2,538 interviews to reflect the estimate that 63.2 percent of the U.S. Hispanic population is Mexican. In the end, the combination of these five files accurately represents the overall U.S. Hispanic population.
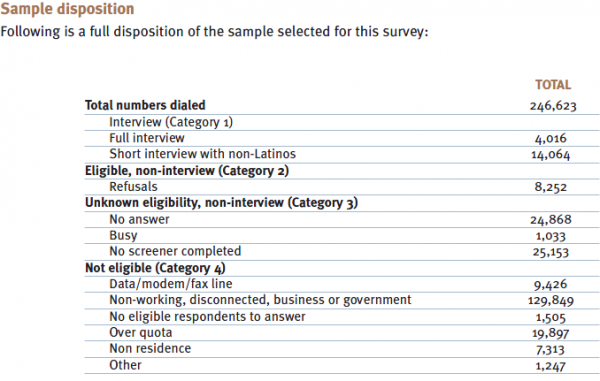
Sample disposition
Following is a full disposition of the sample selected for this survey:
Methodology report – recontact survey of Catholics
In the main survey described above, a total of 2,025 respondents were identified as Catholic. All of these respondents were recontacted and asked to participate in a new battery of questions. Respondents were offered an incentive of $20 to participate. A total of 650 Catholics (376 charismatic Catholics and 274 other Catholics) were interviewed in the recontact survey. The margins of error for the main groups are as follows:
Catholics: +/-5.7%
Charismatic Catholics: +/-7.7%
Other Catholics: +/-8.5%
Eligible respondent
The re-contact survey was administered to any person ages 18 and older who was of Latino origin or descent and who participated in the first survey and identified as Catholic.
Field period
The field period for this re-contact survey was Jan. 5 to Jan. 29, 2007. The interviewing was conducted by ICR/International Communications Research in Media, Pa. All interviews were conducted using the Computer Assisted Telephone Interviewing (CATI) system. The CATI system ensured that questions followed logical skip patterns and that the listed attributes automatically rotated, eliminating “question position” bias.
Weighting and estimation
Using the data from the original survey, data from the recontact survey of Catholics were weighted by age, gender, education and foreign/native born status, so as to be representative of the sample of Catholics from the original survey.
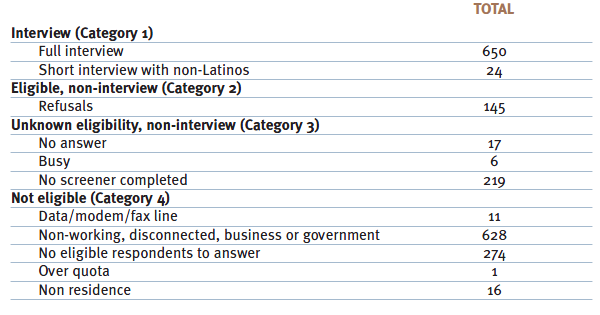
Sample disposition
Following is a full disposition of the sample selected for this survey:
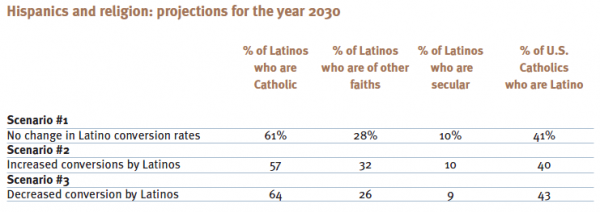
Methodology report – population projections
The Pew Hispanic Center developed estimates of the 2005 civilian, non-institutional population, based in part on the Census Bureau’s 2005 population estimates. The Pew Hispanic Center estimates also incorporated updated estimates of the undocumented population and were specified by age, race/ethnicity, and generation (details in a forthcoming Pew Hispanic Center publication).
Initial religious distributions for non-Hispanics were derived from the Pew 2006 U.S. Religion Survey conducted by the Pew Forum on Religion & Public Life. For Hispanics, initial religious distributions are categorized by generation and are based upon the primary data collection effort for this study. For the purposes of the projections, religion was classified into three categories: Catholic, some other non-Catholic faith and secular.
To project religious distributions into the future, conversion rates were applied to the initial religious distributions among Hispanics and non-Hispanics. The rates of conversion over the next 25 years were estimated to mirror the rates over the past 25 years, which were established through the 2006 Forum Pentecostal Survey (for non-Hispanics) and through the surveys conducted for this study (for Hispanics). Given nativity differences in conversion for Hispanics, the Hispanic conversion rates were further disaggregated by nativity.
Applying the conversion rates to the initial religious distributions produced estimates of the religious distributions for Hispanics and for non-Hispanics for 2030. These religious distributions were then multiplied by the age-specific, race-specific, generation-specific population projections for 2030 to determine the number of Hispanics and non-Hispanics in each religious category, and thus the race/ethnic profile of each of the three religious categories, assuming conversion rates remain constant.
An analogous approach was used to estimate the alternative conversion scenarios. However, instead of assuming that conversion rates would remain constant, the conversion rates away from Catholicism for Hispanics were altered; in one scenario, rates of conversion increased by 50%, and in the other scenario, conversion away from Catholicism decreased by 50%. All three scenarios assumed that conversion rates among non-Hispanics would remain constant.