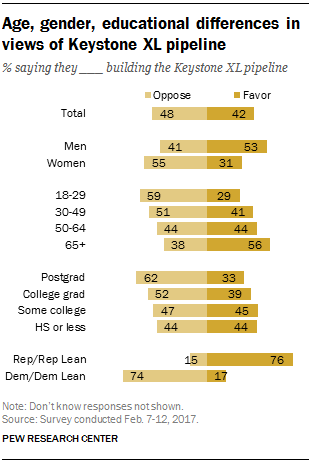
DownloadAge, gender, educational differences in views of Keystone XL pipeline ← Prev Page 1 2 3 Next Page →
{kind=link}