

If you’ve ever had to analyze a set of documents — such as social media posts, open-ended survey responses, focus group transcripts, software logs, etc. — you may have wondered about natural language processing (NLP). NLP is an umbrella term that encompasses a wide variety of algorithmic methods that can be used to automatically analyze large volumes of text.
Some of these methods are “supervised,” which means that they require researchers to first classify a sample set of documents manually. Algorithms can then use these manual classifications to learn word associations well enough to apply the same system to a larger collection of documents. Supervised learning algorithms can save researchers a lot of time, but they still involve extensive and careful reading of documents and detailed categorization.
Other NLP methods are “unsupervised,” which means they don’t require training data classified by people. Instead, these algorithms look at how words are used in the documents you’re examining. They pick up on patterns and provide an estimate of what the documents convey with little direct supervision from the researcher. One of the most popular forms of unsupervised learning for text analysis is topic models, which I’ll be addressing here and in future posts.
A topic model is a type of algorithm that scans a set of documents (known in the NLP field as a corpus), examines how words and phrases co-occur in them, and automatically “learns” groups or clusters of words that best characterize those documents. These sets of words often appear to represent a coherent theme or topic.
There are a variety of commonly used topic modeling algorithms — including non-negative matrix factorization, Latent Dirichlet Allocation (LDA), and Structural Topic Models. Ongoing research has produced other variants as well. At Pew Research Center, we’ve been testing some of these algorithms and exploring how topic models might be able to help us analyze large collections of text, such as open-ended survey responses and social media posts. Here, I’ll be exploring a dataset consisting of open-ended responses to a survey about what makes life feel fulfilling. All we need to train the model is a spreadsheet with a single column of text, one response (i.e. document) per row.

How topic models work
In one way or another, every topic modeling algorithm starts with the assumption that your documents consist of a fixed number of topics. The model then assesses the underlying structure of the words within your data and attempts to find the groups of words that best “fit” your corpus based on that constraint. At the end, you’re left with two output tables: the term-topic matrix, which breaks topics down in terms of their word components, and the document-topic matrix, which describes documents in terms of their topics. Depending on the specific algorithm that you use, a word may be assigned to multiple topics in varying proportions, or assigned to a single topic exclusively.
Let’s consider the below example of a term-topic matrix, which is based on topics from a model trained on our open-ended responses. (The topics are real but for simplicity the numbers and documents here are illustrative and not based on actual data.) The first column contains an arbitrary identifier for each topic so we can refer to each topic by a name, followed by a column for every possible word that each topic could contain (known as our “vocabulary”). The values in the cells indicate how much each word “belongs” to each topic. Their exact meaning will depend on the specific algorithm used, but usually the most common value in this table will be zero (or close to it), since only a fraction of our vocabulary will be at all relevant to any particular topic. Since these tables can become enormous, the example below shows just three topics and a few of their top words.
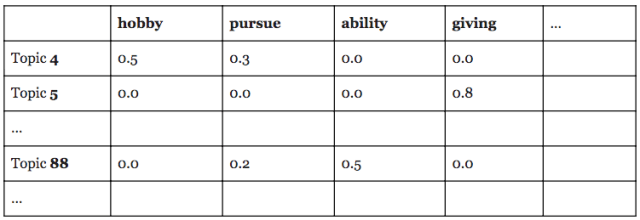
Since this raw output can be difficult to read and interpret, researchers often sort through the words for each topic and pick out the top words based on some measure of importance. For models that assign words to topics proportionally, we can look at the words that have the highest weights for each topic — that is, those that make up the greatest share of the topic. We can also use other metrics, like mutual information, to compare the words in each topic against all of the other topics, and pick out the words that are most distinctive. Using one of these sorting methods, we can select the five or 10 most important words for each topic, making it easier for us to view and interpret them:

If our goal is simply to get a better sense of what’s in our documents, then we may have already accomplished our mission. In cases where we have a large collection of text but don’t really know the nature of its contents, topic models can help us get a glimpse inside and identify the main themes in our corpus. Topic 4 shows us that some of our documents have something to do with the pursuit of hobbies and passions for fun. Topic 5 seems to have something to do with charity and giving back to society, and Topic 88 touches on a more general notion of spending time pursuing and contributing to more serious things, like work. But you may also have noticed some quirks or irregularities in these topics. While each group of words seems to be capturing a distinct theme, all three are somewhat difficult to interpret precisely, and some words look a little out of place.
Using topic models to classify documents
Despite those quirks, we can still use this topic model for a rough categorization of individual documents, which can be useful if we want to make comparisons between documents and analyze how different themes are distributed. To do so, we need to examine the other side of the model’s output, the document–topic matrix.
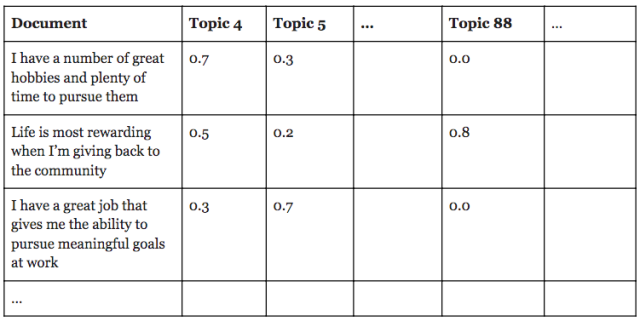
Most topic models break down documents in terms of topic proportions — for example, a model might say that a particular document consists 70% of one topic and 30% of another — but other algorithms may simply classify whether or not a document contains each topic. When using a model that allocates topics to documents as proportions, researchers can analyze the topics as either continuous variables, or as discrete classifications by setting a cutoff threshold to decide whether a document contains a topic or not. Here’s an example of what the corresponding weights for our three example documents might look like, for the three different topics above:
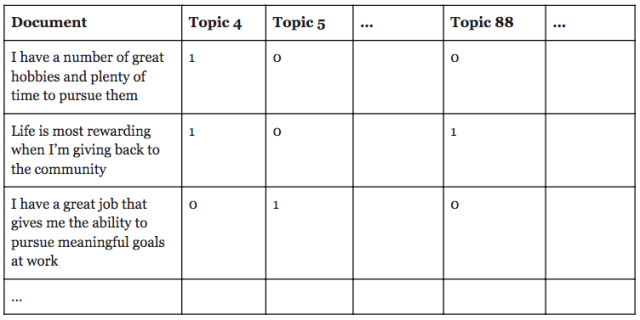
By setting a 50% cutoff threshold, we can also turn these into categorical variables, like those you might collect in a survey:
When you first see topic model output, it can be inspiring. Having the ability to automatically identify and measure the main themes in a collection of documents opens the door to all kinds of exciting research questions, and you may find yourself eager to get started. However, it turns out that running the topic model is the easy part — and the first of several steps. Before we can use our model as a measurement tool, we also have to figure out what it’s measuring — an undertaking that can be surprisingly difficult. In my next post, I’ll explain why.