

There are a variety of tools that can help researchers analyze large volumes of written material. In this post, I’ll examine two of these tools: part-of-speech tagging and tone analysis. I’ll also show how to use these methods to find patterns in a large set of Facebook posts created by members of Congress.
Part-of-speech (POS) tagging is a process that labels each word in a sentence with an algorithm’s best guess for the word’s part of speech (for example, noun, adjective or verb). This is based on both the definition of each word and the context in which it appears. There are several libraries in Python that perform POS tagging, such as NLTK, SpaCy and TextBlob. These tagging systems are pre-trained using supervised machine learning models, based on a training dataset with labeled text. As a result, the POS tags returned by these models are estimates based on the data that each particular model was trained with.
One reason researchers might care about parts of speech is that they can help reveal attributes of written text. For example, research has shown the presence of adjectives and adverbs is usually a good indicator of text subjectivity. In other words, statements that use adjectives like “interesting,” “problematic” and “awesome” might be more likely to convey a subjective point of view than statements that do not include those adjectives. Adjectives and adverbs might also be especially likely to convey tone: Some indicate more positive qualities, while others indicate negative qualities.
To identify adjectives using a computational model, I’ll use a set of predefined part of speech tags. The set of possible tags comes from the Penn Treebank tagset. If the returned tag is either JJ (adjective), JJR (adjective, comparative) or JJS (adjective, superlative), I’ll treat the word as an adjective. Similarly, if a word has the POS tag of RB (adverb), RBR (adverb, comparative) or RBS (adverb, superlative), I’ll consider it an adverb.
The code below is a simple function in Python that returns a list of all adjectives and adverbs, and the total number of adjectives and adverbs for a given text using the TextBlob library:
from textblob import TextBlob
from collections import Counterdef textblob_adj(text):
blobed = TextBlob(text)
counts = Counter(tag for word,tag in blobed.tags)
adj_list = []
adv_list = []
adj_tag_list = [‘JJ’,’JJR’,’JJS’]
adv_tag_list = [‘RB’,’RBR’,’RBS’]
for (a, b) in blobed.tags:
if b in adj_tag_list:
adj_list.append(a)
elif b in adv_tag_list:
adv_list.append(a)
else:
pass
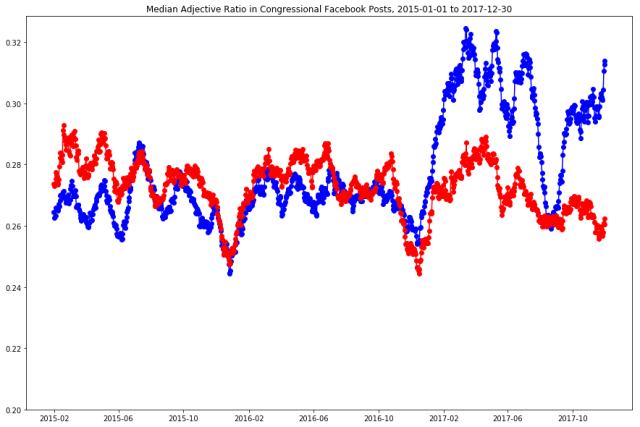
return adj_list, adv_list, counts[‘JJ’]+counts[‘JJR’]+counts[‘JJS’], counts[‘RB’]+counts[‘RBR’]+counts[‘RBS’]To show how part-of-speech recognition works in practice, I analyzed over 700,000 Facebook posts created between Jan. 1, 2015, and Dec. 30, 2017, by members of the U.S. Congress, collected using Facebook’s public API. (This is part of a larger body of research that Pew Research Center has conducted about lawmakers’ Facebook posts.) My goal was to understand how adjective and adverb use in partisan speech changed across this period of time. The analysis shows that after President Donald Trump took office, Democrats in Congress started using more adjectives than Republicans in their Facebook posts. Democrats’ ratio of positive to negative adjectives also decreased after Trump took office.
I applied the function above to each Facebook post. Some of the adjectives that were used mostly by Democrats in Congress include “wealthiest”, “richest” and “reproductive,” whereas “unborn,” “libertarian” and “Islamist” are among the adjectives used mostly by Republicans. The adjective ratio — defined as the number of adjectives divided by the total number of words in the post — was slightly higher for Republicans than Democrats in the early part of 2015. It was very similar for the two parties across most of 2016. But starting with Trump’s 2016 election victory, Democrats became much more likely to use adjectives in their posts. This finding aligns with a previous Pew Research Center analysis that shows that congressional Democrats expressed political opposition more frequently under Trump. It is also consistent with the hypothesis that adjective use is linked with stronger emotions.
I also examined the tone of particular adjectives by comparing the words that appeared in the congressional posts with a list of adjectives that usually have a positive or negative association. This association is based on a polarity dictionary: a list of positive and negative words. If an adjective appears in the list of positive or negative words in the dictionary, it is classified as such. The plot produced here uses the Harvard IV-4 dictionary, which contains 1,915 positive and 2,291 negative words (the list is also used in the academic community).
Using that measure, the ratio of positive to negative adjectives declined in congressional Democrats’ Facebook posts after Trump was inaugurated, but it increased slightly in Republicans’ posts (I added 1 to the denominator to avoid dividing by 0). For much of the first half of 2015, Republicans had a lower positive-to-negative adjective ratio, but the partisan difference was absent across most of 2016.
Adjective analysis using off-the-shelf packages and dictionaries can provide an accessible and inexpensive way to explore sentiment and subjectivity in texts, without the need to obtain a large labeled training set. However, researchers should be cautious when drawing inferences from the tools described here. There’s no guarantee that adjectives provide a valid measure of important concepts like subjectivity across diverse contexts, and the link between particular adjectives and sentiment may not generalize across different domains. It’s always necessary to validate a given model — either by using human coders, or by supplementing the analysis with other measures of subjectivity — before drawing strong conclusions about what text tells us.