
Many of Pew Research Center’s survey analyses show relationships between two variables. For example, our reports may explore how attitudes about one thing — such as views of the economy — are associated with attitudes about another thing — such as views of the president’s job performance. Or they might look at how different demographic groups respond to the same survey question.
But analysts are sometimes interested in understanding how multiple factors might contribute simultaneously to the same outcome. One useful tool to help us make sense of these kinds of problems is regression. Regression is a statistical method that allows us to look at the relationship between two variables, while holding other factors equal.
This post will show how to estimate and interpret linear regression models with survey data using R. We’ll use data taken from a Pew Research Center 2016 post-election survey, and you can download the dataset for your own use here. We’ll discuss both bivariate regression, which has one outcome variable and one explanatory variable, and multiple regression, which has one outcome variable and multiple explanatory variables.
This post is meant as a brief introduction to how to estimate a regression model in R. It also offers a brief explanation of some of the aspects that need to be accounted for in the process.
Bivariate regression models with survey data
In the Center’s 2016 post-election survey, respondents were asked to rate then President-elect Donald Trump on a 0–100 “feeling thermometer.” Respondents were told, “a rating of zero degrees means you feel as cold and negative as possible. A rating of 100 degrees means you feel as warm and positive as possible. You would rate the person at 50 degrees if you don’t feel particularly positive or negative toward the person.”
We can use R’s plot function to take a look at the answers people gave. The plot below shows the distribution of the ratings of Trump. Round numbers and increments of 5 typically received more responses than other numbers. For example, 50 had a larger number of responses than 49.
In most survey research we also want to represent a population (in this case, the adult population in the U.S.), which requires weighting the data to known national statistics. Weights are used to correct for under- and overrepresentation among different demographic groups in our sample (like age, gender, region, education, race). When working with weighted survey data, we need to account for these weights correctly. Otherwise, population estimates, standard errors and significance tests will be incorrect.
library(survey)
library(dplyr)
library(haven)atp_w23<-read_sav(“ATP W23.sav”)%>% as_factor
###### Recoding the Trump variable to be a numeric
## This variable was stored as a factor variable, “as.character”
## coerces factor to string. “as.numeric” will convert the string
## variable to a numeric
## variable and set the ‘refused’ category to missing by default
atp_w23 <- atp_w23 %>% mutate(
THERMO2_THERMTRUMP_W23 = case_when(
THERMO2_THERMTRUMP_W23 == “Refused” ~ NA_real_,
TRUE ~ as.numeric(as.character(THERMO2_THERMTRUMP_W23))
)
)
## The variables that will be used include:
# WEIGHT_W23: Survey weight for ATP Wave 23
# F_PARTYSUM_FINAL: Respondent party ID with leaners included in
# each party
# F_RACETHN_RECRUITMENT: Respondent race/ethnicity (4 categories)
# THERMO2_THERMTRUMP_W23: Trump thermometer
### Distribution Plot
### Obtain the weighted share of the population at each therm ratingwgt_dist <- atp_w23 %>%
group_by(THERMO2_THERMTRUMP_W23) %>%
summarise(WEIGHT_W23 = sum(WEIGHT_W23))## Open a plot windowplot(0,0, pch = ‘’, xlab = “Rating of Trump”, ylab = “Count”,
main = “Distribution Plot”, axes = FALSE, xlim = c(0,100),
ylim = c(0, max(wgt_dist[[2]])))
axis(1, at = seq(from = 0, to = 100, by = 5))
axis(2)## Plot the distribution of Trump thermometer scoressegments(x0 = wgt_dist[[1]], x1 = wgt_dist[[1]],
y0 = rep(0, nrow(wgt_dist)), y1 = wgt_dist[[2]], lwd = 2)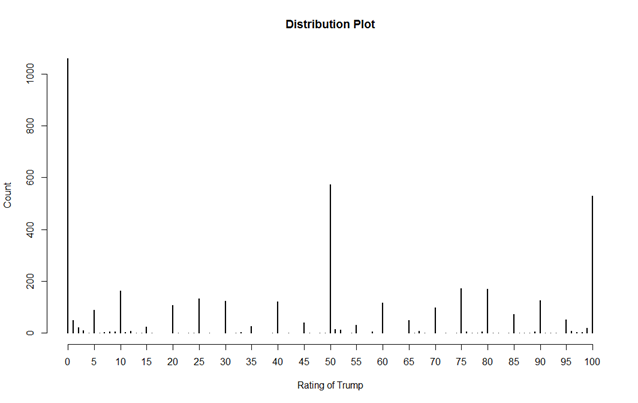
One option for working with survey data in R is to use the “survey” package. For an introduction on working with survey data in R, see our earlier blog post.
The first step involves creating a survey design object with our weights variable. Below, we define the “d_design” object with the corresponding weight from the WEIGHT_W23 variable. We can use this survey object to perform a wide variety of analyses included in the `survey` package. In this case, we’ll use it to calculate averages and run a regression.
The `svymean()` function lets us calculate Trump’s average thermometer rating and its standard error. Overall, the average rating of Trump among those who gave him a rating in this data is 43, but we know from existing research that public views of Trump differ substantially by race, among other things. We can see this by tabulating the average Trump thermometer score by the race/ethnicity variable in the dataset (“F_RACETHN_RECRUITMENT”). The `svyby()` function lets us do that separately for each race category:
## Estimate weighted means by race/ethnic categories
d_design <- svydesign(id=~1, weights=~WEIGHT_W23, data=atp_w23)
svymean(~THERMO2_THERMTRUMP_W23, design = d_design, na.rm = TRUE)
svyby(~THERMO2_THERMTRUMP_W23, ~F_RACETHN_RECRUITMENT, design =
d_design, FUN = svymean, keep.names = FALSE, na.rm = TRUE)
F_RACETHN_RECRUITMENT THERMO2_THERMTRUMP_W23 se
1 White non-Hispanic 49.26768 1.183910
2 Black non-Hispanic 25.55557 2.577569
3 Hispanic 29.48770 2.593483
4 Other 40.08294 3.633176
5 Don’t know/Refused (VOL.) 67.38704 8.171415We can see that there is a large difference between whites, blacks and Hispanics, with whites rating Trump at least 23 points higher than the other racial/ethnic groups do. (The “other” and “don’t know/refused” categories account for about 7% of the public.) However, since we know that there are large racial and ethnic differences in party identification, it may be that the racial divide in Trump ratings is a function of partisanship. This is where regression comes in.
By using the regression function `svyglm()` in R, we can conduct a regression analysis that includes party differences in the same model as race. Using `svyglm()` from the survey package (rather than `lm()` or `glm()`) is important because it accounts for the survey weights while estimating the model. The output from our `svyglm()` function will allow us to see whether a racial gap persists even after accounting for differences in partisanship between racial groups.
First, we can look at the results when we only include race in the regression:
summary(svyglm(THERMO2_THERMTRUMP_W23 ~ F_RACETHN_RECRUITMENT, design = d_design))
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 49.268 1.184 41.614 < 2e-16 ***
F_RACETHN_RECRUITMENTBlack non-Hispanic -23.712 2.836 -8.360 < 2e-16 ***
F_RACETHN_RECRUITMENTHispanic -19.780 2.851 -6.938 4.59e-12 ***
F_RACETHN_RECRUITMENTOther -9.185 3.821 -2.404 0.0163 *
F_RACETHN_RECRUITMENTDon’t know/Refused (VOL.) 18.119 8.257 2.194 0.0283 *
— -
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1When interpreting regression output, we want to examine the coefficients of the independent variables. These are given by the values in the “Estimate” column.
Notice that the estimate and standard error for the “(Intercept)” are identical to the values we calculated earlier for white non-Hispanics. By default, R treats the first category in an independent variable as the reference category. The coefficients for the other racial groups show how each group differs from whites in terms of the Trump thermometer score. Notice that the coefficients for blacks, Hispanics and those who identify with other racial groups are all negative. This means that, on average, the ratings of Trump are lower across each of these groups compared to whites. For example, the coefficient for blacks is -23.7. This can be interpreted as meaning that, on average, Trump’s thermometer rating is 23.7 points lower for blacks than for whites. If we think back to the overall averages, this makes sense because all the nonwhite racial/ethnic groups rated Trump lower than whites did. And, in fact, if you combine the intercept estimate with the estimate for non-Hispanic blacks, you get 49.3–23.7 = 25.6, exactly what we saw in the simple tabulation above.
Multiple regression models with survey data
Regression becomes a more useful tool when researchers want to look at multiple factors simultaneously. If we want to know whether the racial divide persists even after accounting for differences in party identification, we can enter partisanship into the regression equation. Note that the only difference here is one added explanatory variable (F_PARTYSUM_FINAL) which contains responses to questions about which political party the respondents identify with or lean toward. Since we have two independent variables now, the reference categories are now the group of people who are in the first level for the F_RACETHN_RECRUITMENT and F_PARTYSUM_FINAL variables. In this case, that means that the intercept is the expected average thermometer score among non-Hispanic whites who also identify as or lean Republican.
summary(svyglm(formula = THERMO2_THERMTRUMP_W23 ~
F_RACETHN_RECRUITMENT +
F_PARTYSUM_FINAL, design = d_design))
Call:
svyglm(formula = THERMO2_THERMTRUMP_W23 ~ F_RACETHN_RECRUITMENT + F_PARTYSUM_FINAL, design = d_design)
Survey design:
svydesign(id = ~1, weights = ~WEIGHT_W23, data = atp_w23)
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 71.817 1.243 57.778 < 2e-16 ***
F_RACETHN_RECRUITMENTBlack non-Hispanic -2.066 2.878 -0.718 0.4728
F_RACETHN_RECRUITMENTHispanic -4.864 2.691 -1.808 0.0707 F_RACETHN_RECRUITMENTOther 2.429 3.089 0.786 0.4316
F_RACETHN_RECRUITMENTDon’t know/Refused (VOL.) 12.338 11.623 1.062 0.2885
F_PARTYSUM_FINALDem/lean Dem -50.862 1.814 -28.032 < 2e-16 ***
F_PARTYSUM_FINALDK/Ref-no lean -39.362 4.985 -7.896 3.66e-15 *** — -
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for gaussian family taken to be 691.2602)
Number of Fisher Scoring iterations: 2After including a new variable for partisanship, the racial and ethnic differences almost entirely disappear. The coefficients are quite small (none exceed 5) and are not statistically significant at p < 0.05. For blacks, we can interpret the coefficient of -2.1 as meaning that if we hold party constant, race does not explain differences in Trump’s rating. We would expect both black and white Republicans to give similar ratings of Trump. Likewise, we would expect only small differences between white and black Democrats. In contrast, party matters a lot: Democrats rate Trump about 51 points lower than Republicans on average. Those who don’t lean toward either party rate Trump about 39 points lower than Republicans.
Further analysis could be conducted to explore how other factors might account for variance in Trump thermometer ratings. Perhaps there are significant interactions that we haven’t accounted for (e.g., it might be the case that there is some kind of interaction between race and partisanship that isn’t accounted for in the simple additive model that we looked at above), and it is always important to remember that standard regression analysis of the kind presented in this post is not sufficient to show causal relationships. Regression allows us to sort out the relationships between many variables simultaneously, but we can’t say that just because a significant relationship was found between two variables, one causedthe other. Regression is a useful tool for summarizing descriptive relationships, but it is not a silver bullet (see this post for more on where regression can go wrong).
library(survey)
library(dplyr)
library(haven)
atp_w23<-read_sav(“ATP W23.sav”) %>% as_factor
###### Recoding the Trump variable to be a numeric
## This variable was stored as a factor variable, “as.character” coerces factor
## to string. “as.numeric” will convert the string variable to a numeric
## variable and set the ‘refused’ category to missing by default
atp_w23 <- atp_w23 %>%
mutate(
THERMO2_THERMTRUMP_W23 = case_when(
THERMO2_THERMTRUMP_W23 == “Refused” ~ NA_real_,
TRUE ~ as.numeric(as.character(THERMO2_THERMTRUMP_W23))
)
)
## The variables that will be used include:
# WEIGHT_W23: Survey weight for ATP Wave 23
# F_PARTYSUM_FINAL: Respondent party ID with leaners
# F_RACETHN_RECRUITMENT: Respondent race/ethnicity (4 categories)
# THERMO2_THERMTRUMP_W23: Trump thermometer
###### Distribution Plot
###### Obtain the weighted share of the population at each therm rating
wgt_dist <- atp_w23 %>%
group_by(THERMO2_THERMTRUMP_W23) %>%
summarise(WEIGHT_W23 = sum(WEIGHT_W23))
## Open a plot window
plot(0,0, pch = ‘’, xlab = “Rating of Trump”, ylab = “Count”,
main = “Distribution Plot”, axes = FALSE, xlim = c(0,100),
ylim = c(0, max(wgt_dist[[2]])))
axis(1, at = seq(from = 0, to = 100, by = 5))
axis(2)
## Plot the distribution of Trump thermometer scores
segments(x0 = wgt_dist[[1]], x1 = wgt_dist[[1]],
y0 = rep(0, nrow(wgt_dist)), y1 = wgt_dist[[2]],
lwd = 2)
## Estimate weighted means by race/ethnic categories
d_design <- svydesign(id=~1, weights=~WEIGHT_W23, data=atp_w23)
svymean(~THERMO2_THERMTRUMP_W23, design = d_design, na.rm = TRUE)
svyby(~THERMO2_THERMTRUMP_W23, ~F_RACETHN_RECRUITMENT, design = d_design,
FUN = svymean, keep.names = FALSE, na.rm = TRUE)
summary(svyglm(THERMO2_THERMTRUMP_W23 ~ F_RACETHN_RECRUITMENT, design = d_design))
summary(svyglm(formula = THERMO2_THERMTRUMP_W23 ~ F_RACETHN_RECRUITMENT +
F_PARTYSUM_FINAL, design = d_design))


