
(Related posts: How we adopted Kubernetes for our data science infrastructure, How Pew Research Center uses git and GitHub for version control, How we built our data science infrastructure at Pew Research Center)
At Pew Research Center, we work hard to ensure the accuracy of our data. A few years ago, one of our survey researchers described in detail the process we use to check the claims in our publications. We internally refer to this process as a “number check” – although it involves far more than simply checking the numbers.
As part of our quality control process, we also verify that the code that generates results is itself correct. This component of the process is especially important for our computational social science work on the Data Labs team because code is everywhere in our research, from data collection to data analysis. In fact, it is so central that on Labs we have spun off the review of our code into two distinct steps that precede the number check: a series of interim reviews that take place throughout the lifetime of a project, and a more formalized code check that happens at the end. This is our adaptation of what software developers call “code review.”
This post describes that process – how it works, what we look for and how it fits into our overall workflow for producing research based on computational social science.
Interim reviews
We have learned over the years that a good quality control process for code should move alongside the research process. This helps avoid building our results on top of early mistakes that accumulate and are difficult to fix right before publication. As a result, all projects receive at least one interim review well in advance of having a finished report in hand.
What we look for
The main goal of our interim reviews is to serve as midway checks to ensure that code is readable and properly documented – that is, to make sure it’s easy for other researchers from our team and elsewhere to understand. In that sense, the code reviewer stands in for a potential future reader and points out areas in which the code could, for instance, be easier to follow or need extra documentation.
These are the kind of things that we check for:
- Is the code organized using our internal project template? We use a custom
cookiecuttertemplate to make sure that all our repositories have clear, predictable folder names and that they always include standard integrations. - Are all the scripts included in the GitHub repository? Does the code load all the packages it needs to run? Are the datasets it uses stored in locations other researchers on the team can access?
- Do all scripts include a top-level description of what they accomplish? Are all scripts organized sensibly? Does the description of every function match what the function does? Are all inputs and outputs for functions and scripts documented correctly?
- Are all object names sufficiently informative? Do they follow our internal style guide? For instance, we follow the
tidyversestyle guide for R, which defines a common standard to determine good and bad names for things like functions and variables (such as a preference forsnake_caseversuscamelCase). - Is the code idiomatic and easy to follow? Does it use custom functions that could be replaced with more standard ones? Does it use trusted external libraries? If the analysis consumes a lot of computational resources, are there changes that could make the code more efficient?
How interim reviews benefit our work
There are two main advantages to having these small, periodic checkpoints during the research process. First, they help reduce the burden of the final review by making sure that the code is intelligible along the way. The interim reviews create opportunities for researchers to clean up and document code in manageable chunks.
Second, and more importantly, these interim reviews can catch errors early in the research process, long before we get to a final review. By focusing on whether someone else can follow what is happening throughout the code, these reviews are also excellent opportunities for the authors to confirm that their technical and methodological choices make sense to another researcher.
Things to watch for
In our experience, this level of review calls for a balance that is sometimes tricky to find. On the one hand, the reviewer is in a good position to assess whether the code is legible and complies with our internal technical standards. On the other hand, we all have our own personal styles and preferences.
Some of us prefer to use functions from base R while others favor the tidyverse. And while some think that structuring the code in classes and methods is appropriate, others may find it unnecessarily complicated. It can be hard to set aside our own personal tastes when we are commenting on other people’s work. For that reason, we try to distinguish between required changes (for instance, if a function is improperly documented or if code deviates from our internal style guide) and suggested changes (which the researcher may choose to follow or ignore).
The code check
The code check is a thorough and more systematic review of all the project code that takes place before the number check. It is the level of review that verifies the accuracy of the code that produces the published results. It’s also our last opportunity to catch errors, and, because of that, it is a very intense process.
What we look for
The code reviewer evaluates the project code line by line, assessing whether it does what the researchers say it does. Every code reviewer performs this review in their own way, but it’s useful to think of this process as evaluating three different things:
- Do the researchers’ analytical choices make sense? (Is the method they want to use a sensible way of analyzing the data given their research question?)
- Did the researchers correctly implement their analytical choices? (Are they using a function that performs the method as it’s supposed to?)
- Does the data move through each step in the intended way? (Are the inputs and outputs of each step correct?)
Pew Research Center uses a wide range of technical and analytical approaches in our projects, so it’s almost impossible to come up with an exhaustive list of things that a reviewer must check for. The important thing is to make as few assumptions as possible about what is happening in the code – taking sufficient distance to be able to spot mistakes. For instance, in an analysis that combines survey results with digital trace data from, say, Twitter, these are things a reviewer could check:
- Is the code reading data from the correct time period in our database? Is it using the correct fields? Did the researcher merge the two sources using the correct variable and the correct type of join?
- Is the code dropping cases unexpectedly? Does it generate missing values and, if so, how do they affect the statistical analysis? If we are collapsing categorical variables, are the labels still correct? Because we often do one-off analyses, it’s not always worth writing formal unit tests for the data, so the reviewer has to manually check that the input and output of each function transforming the data is sensible.
- Does the data we’re using align with our research goal? Do the researchers make unwarranted assumptions in the methods they’re using? Do the calculations use the correct base and survey weight? For instance, we frequently study how people use social media sites such as Twitter by linking respondents’ survey answers to their public activity on the platform. However, not every respondent has a Twitter account and not every respondent with a Twitter account will consent to the collection of their Twitter activity. When we report these results, the reviewer has to carefully check the denominators in any proportions: Is this a result about all respondents, respondents who use Twitter, or only respondents who consented for us to collect their behaviors on the site?
- Does the code reproduce the same results that the researchers report when it is executed on a clean environment by the reviewer?
How code checks benefit our work
The code check is always done by a team member who was not involved in the research project in question. A fresh pair of eyes always provides a valuable perspective – for example, about what the researchers want to do and whether their code serves those purposes. In that sense, the code check is our final opportunity to look at a research project as a whole and evaluate whether the decisions we made along the way make sense in retrospect and were implemented correctly.
Having a new researcher look through the whole code has other advantages. The reviewer is expected to run the code top to bottom to confirm that it produces all the figures that we will report. It sounds trivial, but that’s not always the case. It means verifying that that all the code is included in the repository, that all dependencies and their installation are documented properly, that raw data is stored in the correct place, and, finally, that, after running on a new environment, it produces the exact same results that will appear in the final publication. In other words, the final code check tests the reproducibility of our research.
Things to watch for
The purpose of the code check is to evaluate whether the code works as intended or not. Even more than during the interim reviews, reviewers need to focus on evaluating whether the code works as it should and forgo comments about things they might have done differently. By the time the code reaches the code check stage, reviewers should not think about performance or style. Those discussions can happen during the interim reviews instead.
That said, code reviewers are certainly welcome to offer recommendations or suggestions at the code check stage. Learning opportunities abound during this process. But they are asked to be very explicit at this point to distinguish “must-haves” from “nice-to-haves.”
How we use GitHub
We take full advantage of git and GitHub for our code review process. Both the interim reviews and the code check are structured as pull requests that move code from personal branches to shared ones. By doing that, we know that the code in our shared branches (dev during interim reviews, and main after the code check) have been looked at by at least two people, typically including someone who is not a researcher on the project in question. These pull requests are also good starting points to make additional contributions to the project. You can learn more about how we use branches in our Decoded post on version control.
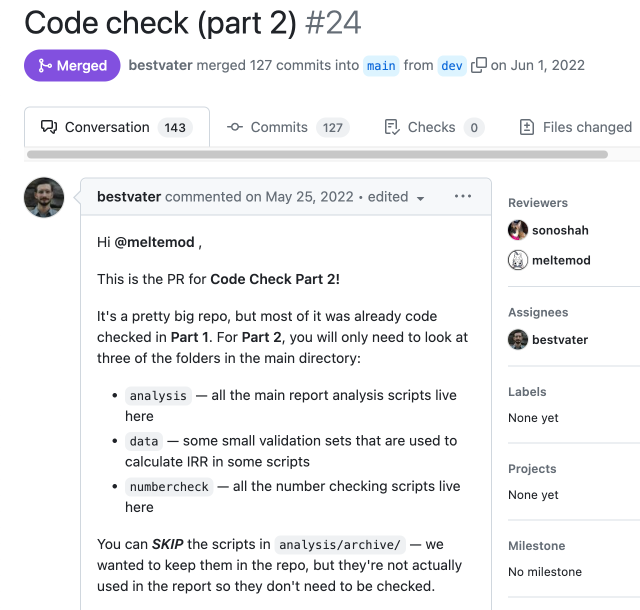
But the major advantage of using GitHub in this process is its interface for pull requests, which allows for discussion. The reviewer can leave comments to alert researchers about potential issues, request additional documentation or add suggestions – always pointing to specific lines of code and with a clear decision at the end (that is, whether the code is OK as it is or whether the authors need to make some edits). If the researchers make changes, the reviewer can see them in the context of a specific request. If they don’t make changes, they can start a discussion thread that gives everyone on the project additional documentation about some of the less obvious technical and methodological choices. This back-and-forth between the reviewer and the researchers continues for as many iterations as needed, until the reviewer’s concerns have been addressed and the code moves on to the corresponding shared branch.
Conclusion
Collectively, these quality control steps help us identify errors. Sometimes these errors are small, like using “less than” instead of “less than or equal to.” Sometimes they’re big, like using the wrong weights when analyzing a survey.
But these steps also help us produce higher-quality work in general. Writing code knowing that other people will need to read, understand and run the code results in clearer, better-documented code. Every moment of review is an opportunity to confirm the quality of the research design. The process is time-consuming, but it’s worthwhile – not just because it ensures that the code is correct, but also because it provides built-in moments to stop, evaluate and discuss the project with others. This results in research that is more readable, reproducible and methodologically sound.




