
(Related posts: An intro to topic models for text analysis, Making sense of topic models, Overcoming the limitations of topic models with a semi-supervised approach, Interpreting and validating topic models and How keyword oversampling can help with text analysis)
In my final post in this series, I’ll discuss the surprising lessons that we learned from a 2018 Pew Research Center study in which we attempted to use topic models to measure themes in a set of open-ended survey responses about the sources of meaning in Americans’ lives.
But first, a quick recap of the steps we took to carry out that study. To begin, we trained semi-supervised topic models on our data and iteratively developed lists of anchor words for the topics to improve the models until the topics looked coherent. We then interpreted the topics by giving them labels and classified samples of responses ourselves using those labels, ultimately arriving at a set of 24 topics that our researchers could label reliably. Our final step was to compare the topic models’ decisions against our own. If the topic models agreed well enough with our own researchers, we hoped to use them to automatically classify our entire dataset of survey responses instead of having to label more responses ourselves.
So how did the topic models do?
The results were somewhat disappointing. The topic models generally performed well, but they failed to achieve acceptable agreement (Cohen’s Kappa of at least 0.7) with our own researchers for six of our 24 final topics. Despite our best efforts to make them as coherent and interpretable as possible using a semi-supervised approach with custom anchor word lists, the topic models’ output simply failed to align with our own interpretation of these six topics.
Not wanting to give up just yet, we also tested a simpler measurement approach: classifying responses based on whether or not they contained any of the words in each topic’s list of anchors. This was far less sophisticated than a topic modeling algorithm, but we were curious to investigate why the models were performing poorly and wanted to establish a baseline level of performance. To our surprise, the keyword searches actually performed equivalent to or better than the topic models, achieving acceptable reliability on all but one of our 24 topics.
For 14 of our 24 topics, the two approaches produced identical results. For these topics, it appeared that the models simply used our suggested anchor terms verbatim and saw no need to make adjustments to better fit the data.
When the models did deviate from the anchor terms, the results were unexpected: For all but one of the remaining topics, the models did notably worse, underperforming the keywords by an average of 14% — an average Kappa of 0.79, compared with 0.91 for the pattern-matching. In just one instance did the topic models manage to outperform the keyword searches, although the difference was negligible (0.96 vs. 0.94). These results were unambiguous: At their best, the topic models were providing virtually no additional value over the raw lists of anchor words we’d used to train them in the first place. And in some cases, they were actually making things worse.
As it turns out, in the process of training our semi-supervised topic models, we had inadvertently compiled our own rudimentary “topic models” by hand — ones that appeared to outperform our actual topic models for the very reasons that drove us to explore a semi-supervised approach in the first place.
Despite our best efforts, when the models actually did what we hoped they would do (use the anchors as a starting point but adapt to the data and pull in new terms), the quirks that the models picked up from idiosyncrasies in our data (e.g., polysemous or conceptually spurious words) far outweighed anything useful they were learning. In some cases, the models also ignored crucial keywords (e.g., “kids,” “children”) even though we encouraged their inclusion via the anchor terms:
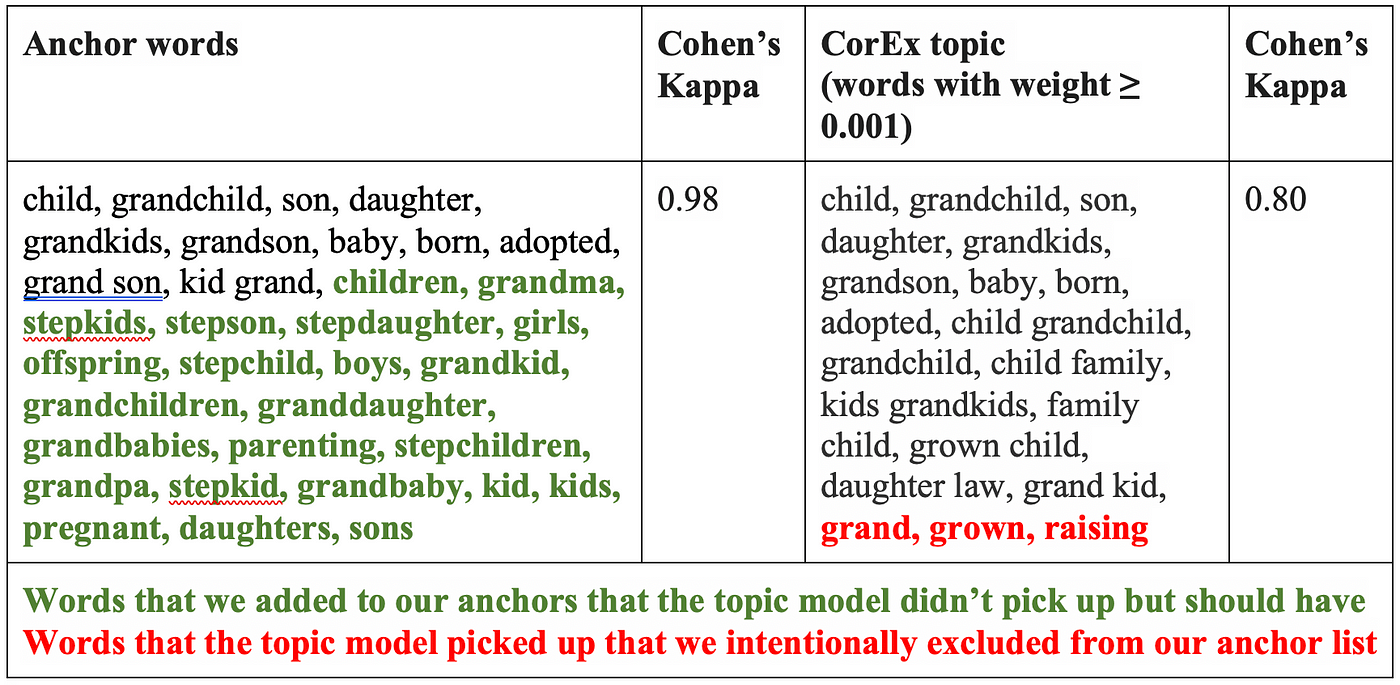
Final thoughts about topic models
After seeing these results, we’ve adjusted how we think about topic models and what they’re good for. Topic models can suggest to us groups of words that might represent coherent themes in our data, and in doing so they can help us rapidly identify patterns in a set of survey responses, social media posts and more. But our attempts to use them as a first-order analysis tool fell short for the following reasons:
- Topic models can be highly sensitive to idiosyncrasies in your data, and interpretation is dependent on context and data. Even though we started with 92 refined CorEx topics that looked coherent and meaningful, we had to abandon 61 of them because they turned out to be too conceptually vague, difficult to interpret or jumbled. This only became clear after extensive exploratory coding that gave us insights into how topics’ words were actually being used in our data.
- It’s difficult to interpret topics and give them clear, well-specified labels. We had to abandon seven of our remaining 31 topics because the descriptive labels we gave them (which seemed perfectly reasonable on paper) were still too poorly specified. This only became clear after extensive manual validation and inter-rater reliability testing.
- Manual validation is the only way to ensure that topics are measuring what you claim they are measuring. Even after assigning reliable definitions to 24 topics — the best-of-the-best topics from multiple painstakingly curated, semi-supervised topic models — we still had to throw out six of them because the topic models’ output didn’t align with our own coding decisions.
- Dictionary-based keyword searches are more reliable. Our manually curated lists of anchor words performed equivalent to or better than the topic models in virtually every case. We were also able to use them to successfully measure five of the six topics where the topic models failed.
Despite these shortcomings, our semi-supervised topic models did serve as an excellent starting point for building our own custom word lists. We were then able to use those lists to classify thousands of survey responses across dozens of categories far more effectively than would have been possible with manual coding or a fully supervised machine learning approach. In fact, after discovering that keyword lists were even more effective than topic models, we circled back to several topics we had discarded earlier in the process because they seemed too difficult to measure. Sidestepping the topic models entirely, we refocused on refining our keywords and topic definitions and were ultimately able to expand the number of topics included in our final analysis from 23 to 30 without much extra work. All in all, the time we spent developing our topic models, manually labeling responses and validating our keyword lists amounted to a fraction of the time we would have spent attempting a traditional hand-coded content analysis.
This insight has already saved us time on other projects, too. In a 2018 study of activism hashtags on Twitter, we were able to read through an exploratory sample of tweets, develop six separate keyword lists, manually classify a validation sample and apply the keyword patterns to over a million tweets — all in a day’s work. Topic models couldn’t provide us with a reliable way to conduct our analysis, but it turns out that even simpler automated methods can enable large-scale analysis with both speed and ease.
With larger datasets or longer documents, it’s possible that topic models could perform better, and we’ll continue looking for opportunities to test these algorithms and understand more about when they work and when they don’t. But for now, the evidence suggests that even with intense curation, scrutiny and validation, topic models are not particularly well-suited for classification. Instead, their strength lies in exploratory analysis, where they can serve as tools of suggestion: Topic models can help guide researchers toward more curated measurement instruments informed by a human understanding of the data, its context and linguistic semantics more broadly.
As for computer-assisted text analysis generally, the future looks bright. New advances are being made every day as researchers develop innovative new methods and refine their understanding of how to apply them with rigor and transparency. But for all of the complexity of modern algorithms, sometimes the simple tried-and-true approach — like hand-picking keywords — can work the best.