
Survey researchers often examine how people’s attitudes and experiences differ depending on their family income. A December 2015 Pew Research Center survey, for example, found that lower-income parents were more likely than those with higher incomes to express concerns about their children being victims of violence or getting in trouble with the law. But family income can be difficult to measure, even for the most well-funded and detailed government surveys.
Pew Research Center has long classified Americans into three simple tiers based on the annual family incomes they report in our surveys: those who earn less than $30,000 a year, those who earn between $30,000 and $74,999 a year, and those who earn $75,000 or more a year. While these categories are a useful analytical tool, they do not necessarily do a good job of capturing whether someone is part of a lower-, middle- or upper-income family. For example, a single person earning $75,000 a year in Pittsburgh — a relatively low-cost area — would be grouped in the same category as a four-person family earning the same amount in San Francisco — a relatively high-cost area — even though their life experiences are likely very different.
With this reality in mind, researchers at the Center decided to incorporate an adjustment to our survey respondents’ family incomes — one that considers differences in purchasing power by household size and geography. This post will walk through this adjustment method in more detail.
The issue with using unadjusted income data
To begin this analysis, it’s helpful to look first at the distribution of household income in the United States in 2019 using the nation’s official source for this kind of information: the Current Population Survey Annual Social and Economic Supplement (CPS ASEC), which is conducted by the U.S. Census Bureau and the Bureau of Labor Statistics.
This survey enjoys the kind of large sample sizes and high response rates that typically only exist in pollsters’ dreams. The CPS ASEC asks a battery of questions about income sources, ranging from wage and salary income to disability benefits. The result is a detailed portrait of U.S. household income. Such precise questions would necessarily take up the entirety of most “standard” public opinion surveys, which already require substantial time and money to get a limited number of people to answer the phone or join an online panel.
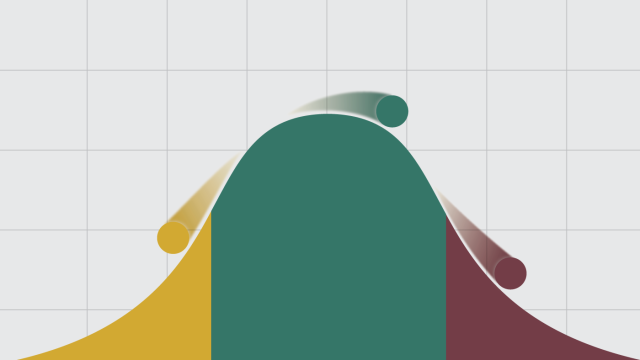
As you can see from the CPS ASEC data, there’s a continuous household income distribution spiking roughly around the median (incomes are adjusted for household size). We study the histogram of the natural log of income because it takes on a normal distribution:

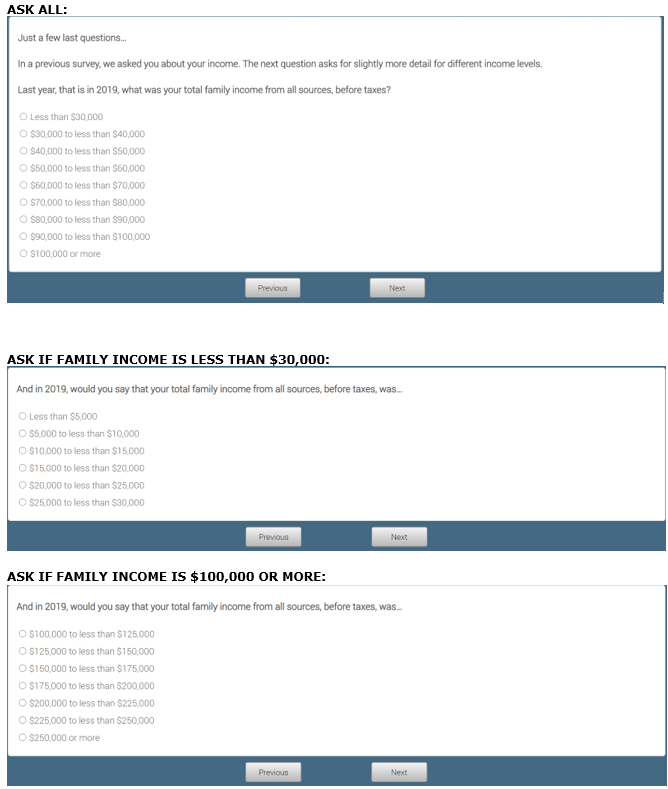
Now, as a comparison, let’s look only at the midpoints of the basic family income categories as reported by Pew Research Center survey respondents. Below, you can see the income questions we used in our most recent American Trends Panel recruitment. We use the midpoints of these categories for analyzing income in our panel (or in the case of the highest income categories, slightly above it):
Looking at a histogram of just these midpoints, you can see that the income distribution has wider tails and appears less continuous:

If we use this latter income distribution as is, we risk underreporting the number of respondents in middle-income families. As a result, we set out to adjust our respondents’ incomes for household size and local cost of living in the hopes of better capturing our respondents’ economic realities.
Adjusting survey respondents’ incomes
Adjusting family incomes is a relatively simple process. First, we merge the Regional Price Parities (RPPs) published by the Bureau of Economic Analysis with our survey respondents’ locations using their documented Federal Information Processing Standards, or FIPS, codes.
The RPP is a price index that measures a region’s price level as a percent of the overall national price level. Any locality with an RPP greater than 100 has a mean price level higher than the national average, while any area with a value less than 100 has lower-than-average prices.
FIPS codes, meanwhile, are unique 5-digit combinations of state and county codes. For example, the FIPS code for Monroe County, New York, is 36055. The number 36 represents the state of New York and 055 represents county number 55.
Since the smallest level of geography available in the RPPs is the metropolitan statistical area (MSA), we utilize a crosswalk to merge the MSA-level RPPs with survey respondents living within constituent counties. Any respondent living in counties outside of an MSA is assigned the non-metropolitan RPP for their respective state. With the RPPs assigned to each person in our survey panel, we take the midpoint of the self-selected family income category and adjust it to account for the local cost of living:

The next step of the adjustment follows the methodology used in Pew Research Center’s previous work on the American middle class by accounting for household size. We divide the family income midpoint by the square root of self-reported household size.
Why the square root instead of income per capita? In reality, there are economies of scale in consumer expenditures. Two-bedroom apartments don’t generally cost double the price of an equivalent one-bedroom, for example. So, the final adjusted income looks like this:

The resulting income distribution now has a closer resemblance to the household-size adjusted income distribution calculated from the CPS ASEC:

The final step of creating our new tiered income variable is straightforward. We classify respondents as lower income if their family income falls below two-thirds of the median adjusted income of our survey panelists; middle income if their income is between two-thirds and double the median; and upper income if their annual family income is greater than double the median. We have found that these new income tiers do a better job as an explanatory variable in our surveys and reports.
Consider an August 2020 Pew Research Center survey, which found that lower-income Americans were the most likely to say that they or someone else in their household had lost a job due to the coronavirus outbreak. This finding was based on our new, adjusted data, accounting for household size and geographic differences in living costs. If we had used only the unadjusted data, we would not have found that lower-income Americans were more likely to have experienced a job loss in their household:

In our full survey panel, 32% of respondents are classified as lower income, 45% are middle income and 19% are upper income. An additional 4% of respondents skipped our income or household size questions, and as a result could not have their family incomes adjusted.
Using our new income tiers moving forward
Each year, Pew Research Center refreshes our survey panel, adding new panelists to replace those who have been lost due to attrition. For each refresh moving forward, this income adjustment and tier replacement will be calculated for the entire panel. Subsequent survey “waves” will have the income tier variable merged on as a standard variable, and the share of lower-, middle- and upper-income adults will vary slightly from survey to survey until the panel is refreshed the following year.
Pew Research Center is always looking for ways to improve our understanding of public opinion, and we hope this new method can improve and expand on how we understand the economic realities of the American public.




