

In two earlier posts on this blog, I introduced topic models and explored some of the difficulties that can arise when researchers attempt to use them to measure content. In this post, I’ll show how to overcome some of these challenges with what’s known as a “semi-supervised” approach.
To illustrate how this approach works, I’ll use a dataset of open-ended survey responses to the following question: “What makes your life feel meaningful, satisfying or fulfilling?” The dataset comes from a recent Pew Research Center report about where Americans find meaning in their lives. (You can read some of the actual responses here.)
As my colleagues and I worked on this project over the past year, we tested a number of computational methods — including several topic modeling algorithms — to measure the themes that emerged from these survey responses. The image below shows a selection of four topics drawn from models trained on our dataset (the topics are shown in the rows). To arrive at these topics, we used three different topic modeling algorithms, two of which are shown in the columns below — Latent Dirichlet Allocation (LDA) and Non-Negative Matrix Factorization (NMF). (More on the third algorithm later.)
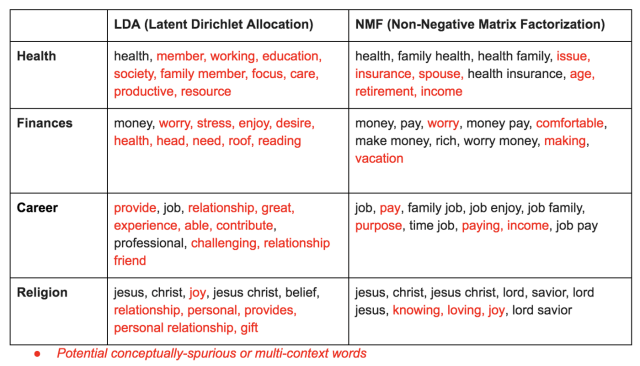
In each of these models, we can clearly see topics related to four distinct themes: health, finances, career and religion (specifically Christianity). But it’s also clear that many of these topics suffer from a few of the problems that I discussed in my last post: Some topics appear to be “overcooked” or “undercooked,” and some contain what might be called “conceptually spurious” words, highlighted above in red. These are words that might apply across multiple contexts and can cause problems under some circumstances.
For example, if our survey respondents only ever mention the word “insurance” when discussing health insurance, it might still fit with a topic intended to measure the concept of “health.” On the other hand, including the word “care” in such a topic might be particularly problematic if, in addition to talking about “health care,” our respondents also frequently use the word to talk about other themes unrelated to health, like how much they care about their families. If that were the case, our model might substantially overestimate the prevalence of the true topic of “health” in our dataset.
For these reasons, our initial attempts at topic modeling Americans’ sources of meaning in life raised some concerns — while we were confident that we could use this method to identify the main themes in our documents, it was unclear whether it could reliably measure those themes. While topic models can be executed quickly, they don’t always make classification decisions as accurately as more complex supervised learning models would — and in some cases their results can be downright misleading.
Fortunately, one recent innovation offered us a compromise between an unsupervised topic modeling approach and a more labor-intensive supervised classification modeling approach: semi-supervised topic models. While still largely automated, the new class of semi-supervised topic models allows researchers to draw on their domain knowledge to “nudge” the model in the right direction.
Intrigued by this possibility, we tested a third algorithm called CorEx (short for Correlation Explanation), a semi-supervised topic model that — unlike LDA and NMF — allowed us to provide the model with “anchor words” that represented potential topics we thought the model should attempt to find. With CorEx, you can also tell the model how much weight it should give to these anchors. If you are less confident in your choices, the model may override your suggestions if they don’t fit the data well enough. Armed with this new ability to guide a topic model with our domain expertise, we set out to assess whether we could make topic models more useful by manually correcting some of the problems we discovered in the above topics.
In training our initial CorEx models, we embraced the reality that no perfect number of topics exists. No matter which parameters you set, a topic model of any size almost always returns at least a handful of jumbled or uninterpretable topics. We decided to train two different models — one with a large number of topics and one with fewer topics — and found that some of the topics that were “undercooked” in the smaller model were successfully split apart in the larger one.
By the same token, “overcooked” topics in the larger model were collapsed into more general and interpretable topics in the smaller one. We didn’t use any anchor words in this first run because we wanted to use the models to identify the main themes in our data and avoid imposing our own expectations about the prominent topics in the responses.
We brought the anchors into play as we reviewed the topics produced by the two models. After getting a sense of the core themes the models were picking up, we selected words that seemed to correctly belong to each topic and “confirmed” them by setting them as anchors. Then, in addition to drawing on our own domain knowledge to expand our lists of anchors with words we knew were related, we also read through a sample of our survey responses and added any relevant words that we noticed the models had missed.
In cases where the models were incorrectly adding “conceptually spurious” words to certain topics, we encouraged the models to pull the undesirable words out of our good topics by adding them to a list of anchor words for a separate “junk topic” that we had designated for this purpose. After re-running the models and repeating this process several times, our anchor lists had grown substantially, and our topics were looking much more interpretable and coherent:
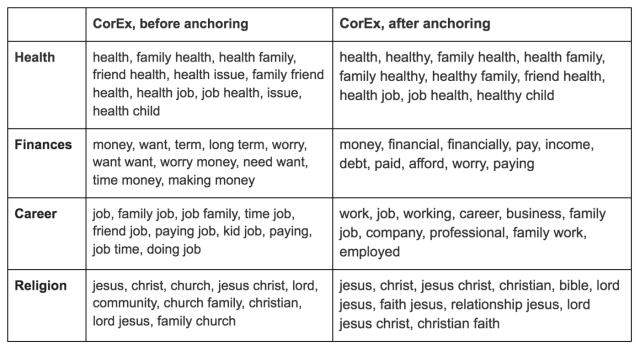
Our application of semi-supervised topic modeling was a game-changer. By guiding the models in the right direction over multiple iterations and careful revisions of our anchor lists, we were able to successfully remove many of the conceptually spurious and multi-context words that appeared in the initial unanchored models. Our topics were looking much cleaner, and we were now hopeful that we could use this approach not only to identify the main topics in our data, but also refine them enough to interpret them, give them clear labels and use them as reliable measurement instruments. In my upcoming posts, I’ll cover how we did just that.
In the meantime, if you’d like to try out semi-supervised topic modeling yourself, here is some example code to get you started.