
Among researchers and computer scientists, the phrase “technical debt” refers to the future costs associated with finicky, fragmentary or slapdash code, database architecture or data processing pipelines. Technical debt does not mean that the code used in a particular research project contains errors. Instead, it describes how a lack of attention to detail in one research project can have compounding effects on future research projects that rely on the same underlying tools. This post explains how technical debt can emerge in social science research, how to identify it and what to do about it.
Consider the following example: Jane is a data scientist at a research organization. She plays an instrumental role in the collection, cleaning, validation and analysis of data. However, she is under constant pressure to publish and promote her work. She can’t always document and test her code to the extent she believes necessary before she is called to add functionality to an existing project or work on something new. Jane is taking on technical debt: Her code works for now, but it might not be reliable or generalizable, and she won’t be able to build on her past work effectively.
So what can social scientists do to avoid amassing technical debt, as Jane has?
Review your code to identify risk
Observing and measuring the technical debt in your research pipelines is as simple as asking yourself (or your colleagues) how much time and energy you are devoting to refactoring or documentation. Refactoring refers to a process similar to editing prose: It involves reviewing code for non-functional purposes in order to improve clarity, style and the use of best practices.
Consider the following two examples of Python code, which tell you whether a given number is prime or not. They both produce the exact same results, but the second has been refactored using the PEP 8 style and incorporates best practices like in-line documentation.
Example 1:
>print(n % 2)
>for i in xrange(2, int(n**.5) + 1):
if n % i ==0:
return False
else:
return True
return TrueExample 2:
def is_prime(n):
“””
Test whether or not an integer is a prime number
:param n: integer:
output bool: True or False
“””
try:
n = int(n) #make sure n is an integer (type = int)
except Exception as e:
print(‘is_prime takes an integer. Is n an integer?’)
if n % 2 == 0:
return False
for i in xrange(2, int(n**.5) + 1):
if n % i ==0:
return False
else:
return True
return TrueThe second example is less likely to cause technical debt headaches for several reasons. First, it includes comments, denoted with # signs. These comments explain choices the researcher has made, without affecting how the code executes. Second, the code contains docstrings, denoted with “””, which describes what the function does at a more general level and what its input and output consists of. Finally, the code is packaged in a named function with meaningful variable names. These each describe what the code actually contains, making it more intelligible.
Remember that all technical debt is not created equal
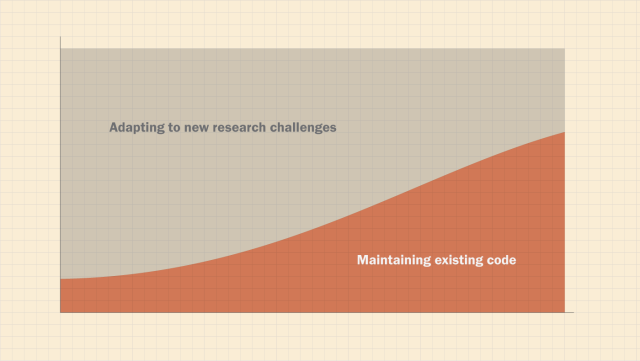
Some forms of technical debt cost more than others. In a research project that frequently undergoes major structural changes — for example, changing data collection pipeline — technical debt is unlikely to persist because the fundamental architecture of the research project is not constant.
But in a stable project, like a database that collects social media posts from a fixed set of accounts or pages on an ongoing basis, technical debt is especially important to address early. Doing so allows researchers to effectively adapt to new challenges — such as changing APIs or social media user behavior — by quickly understanding how those challenges matter for the larger data collection workflow. Documentation, generalizable functions and using a consistent style makes it easier to put out minor fires when they spark.
Collaborate and define ‘done’
There is never a good reason to knowingly write bad code. But bugs and shortcuts are often unavoidable when researchers are eager to start analyzing data. It’s a good idea to implement a code review process in which the author must articulate their logic to other researchers and document their code before any work using it can be released. This will prevent future challenges as the work moves across collaborators and across projects.
As an example, a recent Pew Research Center report that examined public comments to the Federal Communications Commission relied on a small but complex codebase for querying the FCC API and then processing results. Early versions of the code included some shortcuts — for example, the API command was called via client URL, or cURL (cURL is a command line tool for transferring data between different types of protocols, e.g., web) — and the data was not check-pointed. It was then passed through a function called `process` which moved the raw data into the format we wanted.
The code looked like this:
> comments_data = wget(API_PAGE) #pulling the data from the API
> comments = process(comments_data) #store comments metadata in a dataframe
> comments.shapeThis choice didn’t present a problem for the research team; the results were correct. But by not writing more generalizable or commented code, the act of using the same code for processing public comments collected in the future could present potential problems. If the API ever went down, there would be no safeguard and it might easily go unnoticed. To prevent that problem, the research team in this case clearly documented the decisions they made to ensure the code would still be useful for any future work using the same API. When the research team was ready to finalize the analysis, they ensured that other researchers who didn’t work on the project understood what the script was doing.
Short-term investments in reducing technical debt, like code reviews and other quality-control measures, can make a big difference for long-term productivity. Incurring technical debt might allow you to release your project today, but it also comes at a cost: you might need to fix things tomorrow.




